零基础入门PyTorch手写数字识别实战教程(含PyTorch环境搭建)——CNN篇
本文档详细介绍了使用 PyTorch 框架搭建一个简单的手写数字识别系统的全过程。从环境准备到模型训练与测试,每一步都包含详细的代码示例和操作指南。该系统利用卷积神经网络(CNN)处理 MNIST 数据集,旨在为初学者提供一个易于理解且可操作的项目案例。
目录
(1)官网下载(Download Anaconda Distribution | Anaconda)
Index of /anaconda/archive/ | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror
引言
本文档详细介绍了使用 PyTorch 框架搭建一个简单的手写数字识别系统的全过程。从环境准备到模型训练与测试,每一步都包含详细的代码示例和操作指南。该系统利用卷积神经网络(CNN)处理 MNIST 数据集,旨在为初学者提供一个易于理解且可操作的项目案例。通过本教程,你将学会如何:
- 准备必要的开发环境,包括安装 Anaconda、PyTorch(CPU/GPU 版本)和 OpenCV。
- 下载并加载 MNIST 数据集。
- 定义超参数及数据预处理步骤。
- 构建并训练一个基本的卷积神经网络模型。
- 定义损失函数和优化器,实现模型的前向与反向传播。
- 设计并实现模型的训练与测试方法。
- 分析模型在训练集与测试集上的表现,评估模型的准确性和稳定性。
无论你是刚刚接触深度学习的新手,还是希望复习相关知识的老手,希望本文都能提供宝贵的学习资源,最后欢迎各位大佬提出意见,谢谢大家~
一、环境准备
(一)导入必要库
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
import cv2
import numpy as np
from torch.utils.data import DataLoader(二)环境搭建——已搭建可直接跳过
1,Anaconda下载
(1)官网下载(Download Anaconda Distribution | Anaconda)
选择需要的安装包,按提示下载即可。
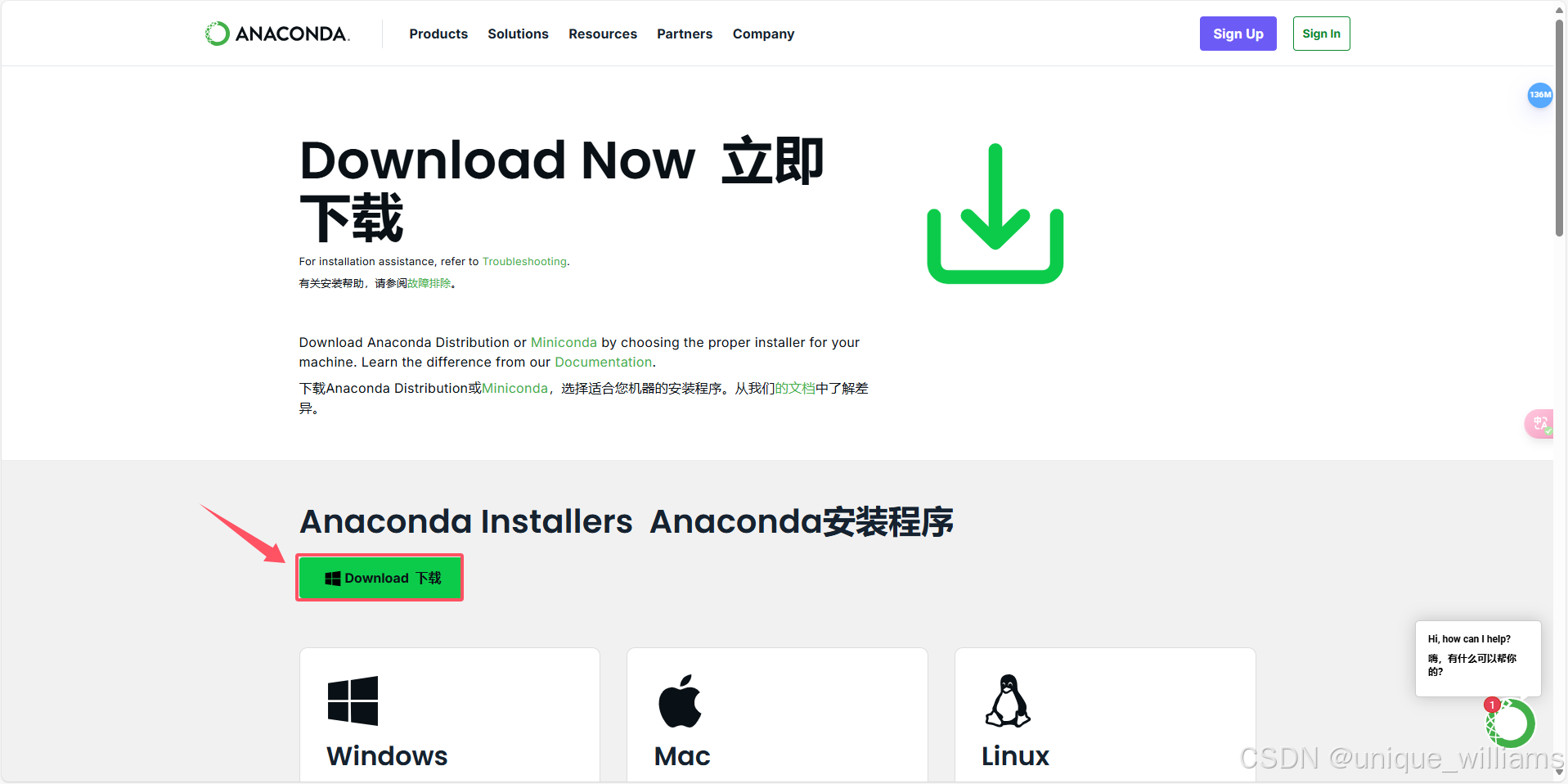
(2)清华镜像网下载(推荐使用)
Index of /anaconda/archive/ | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror
选择最新版本的安装包下载即可

在开始界面搜索 Prompt ,如果出现下方界面代表安装成功,完成后留以备用。如安装遇到问题,可参考北观止大佬的配置教程
(Anaconda基本安装与配置:安装、排错、配置清华源_清华源按照anaconda-CSDN博客)
2,Pytorch安装前检查
安装PyTorch前,需要确定使用的电脑是否安装了N卡(NVIDIA显卡),因为 PyTorch 的GPU版本需要使用N卡来加速计算,判断步骤如下:
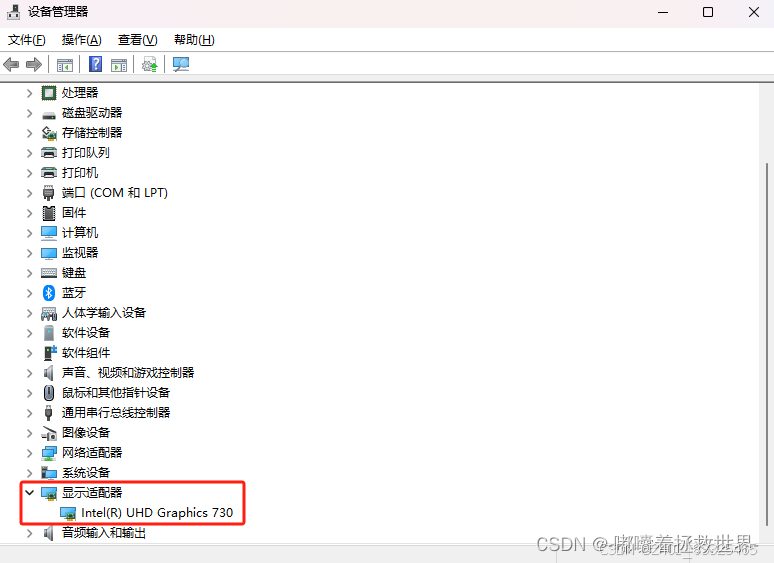
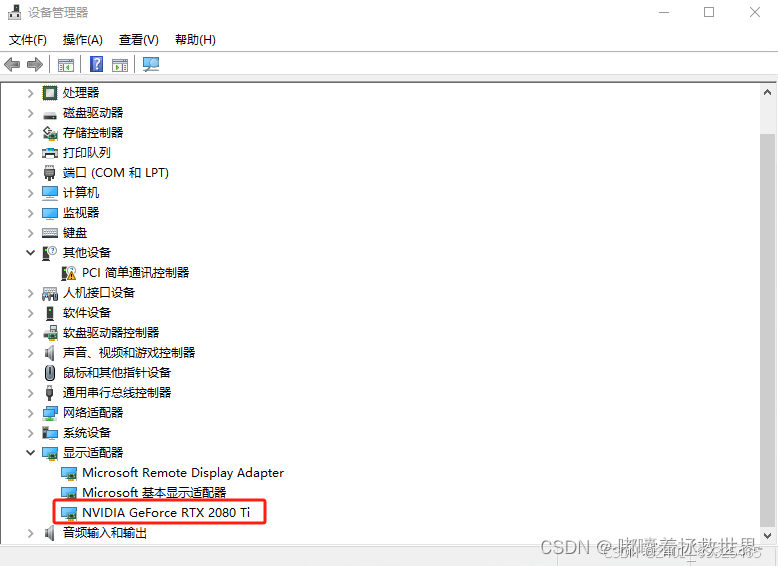
- 打开设备管理器:在Windows上,按下Win键和X键,然后选择“设备管理器”。
- 查看显示适配器:在设备管理器中,展开“显示适配器”或“图形处理器”部分,查看是否有NVIDIA显卡的列表。如果有NVIDIA显卡,那么您的计算机适合安装PyTorch的GPU版本。
(1)电脑未安装N卡
(2)电脑安装N卡
3,PyTorch-CPU版本安装
为了更好地管理不同项目的 Python 环境。通常需要创建一个虚拟环境,用于隔开不同项目之间的依赖项,避免不同项目之间可能发生的冲突问题。以下附虚拟环境创建步骤。
(1)打开命令提示符或PowerShell:开始界面搜索Prompt,打开Anaconda Prompt
(2)创建虚拟环境:运行以下命令创建一个新的虚拟环境。可以将 <env_name> 替换成随意的环境名称(注意:只能是小写字母,出现其他符号会报错)
conda create -n <env_name> python=<version>例如,我要创建一个名为 cvtest 的虚拟环境,其中 python 版本为3.8。
conda create -n cvtest python=3.8
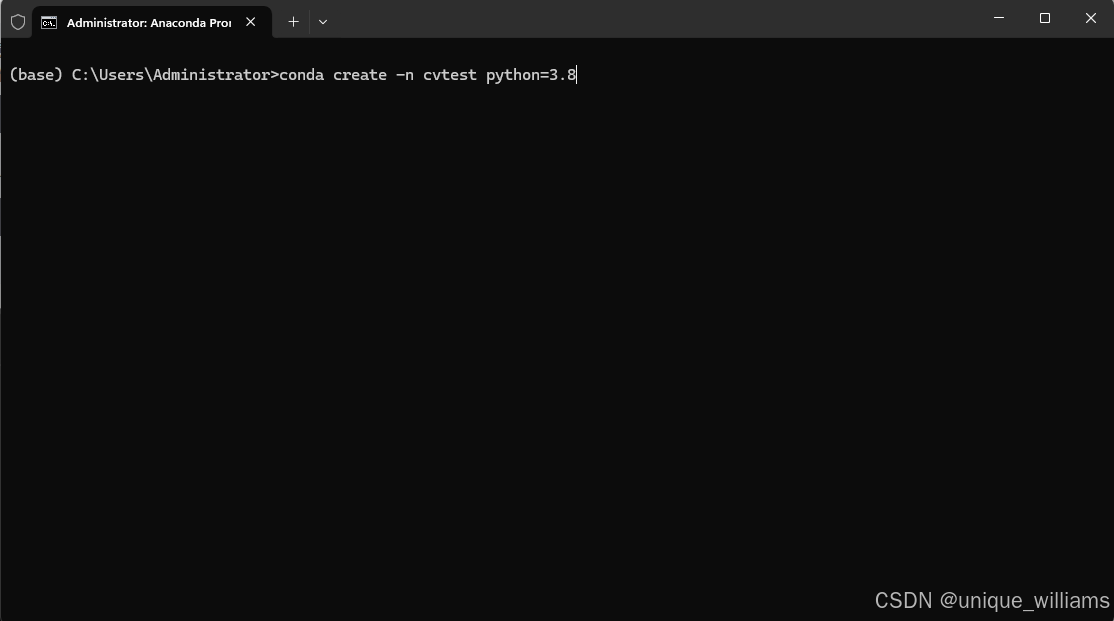
(3)激活虚拟环境:运行以下指令来激活刚刚创建的虚拟环境。在 Windows 上,使用 activate 命令。
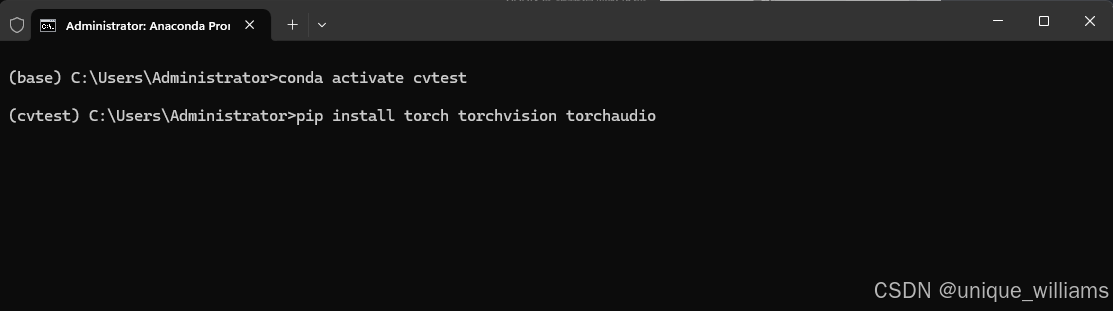
conda activate cvtest激活虚拟环境后,可以看到命令提示符前缀显示为cvtest。这样我们就可以使用该虚拟环境下的 Python 解释器了。

(4)安装 PyTorch(CPU):在激活的虚拟环境中,使用 pip 安装 PyTorch 。根据需求,选择安装的版本。
pip install torch torchvision torchaudio当然可以使用清华镜像源下载。
pip install torch torchvision torchaudio --index-url https://pypi.tuna.tsinghua.edu.cn/simple
(5)检验是否安装成功:安装完后,输入下方指令查看 PyTorch——CPU 版本是否安装成功
pip list
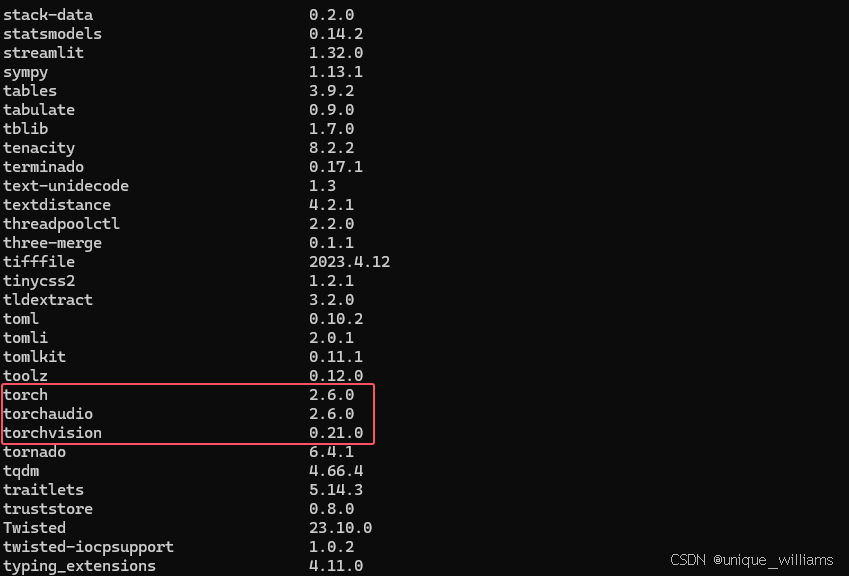
出现以上三行就代表安装成功了(CPU版本)
4,PyTorch-GPU版本安装
(1)查看 CUDA 显卡驱动版本
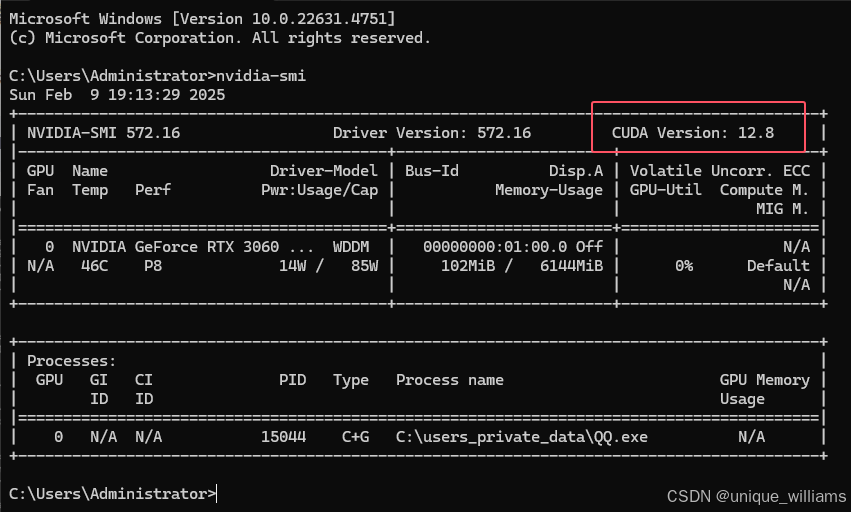
同时按下 WIN + R 键,输入 cmd 打开命令行终端,输入以下指令
nvidia-smi我们可以看到当前版本为12.8
(2)安装 CUDA
从官网下载对应的 CUDA 版本,由于我的显卡版本为12.8,我只需要安装小于或者等于12.8都是可以的,我这里选择12.6.3。
官网(CUDA工具包存档|NVIDIA开发者 --- CUDA Toolkit Archive | NVIDIA Developer)
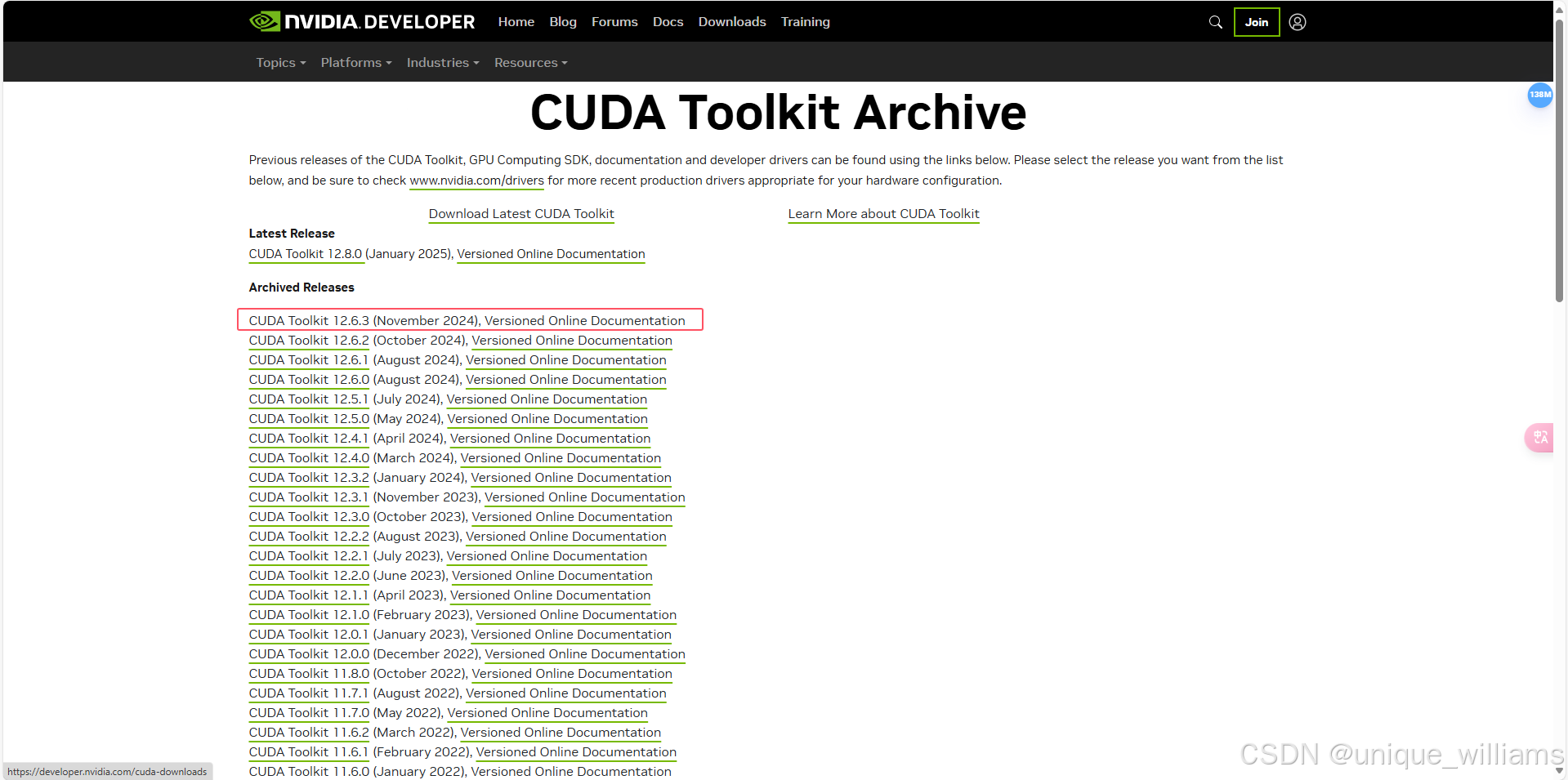
选择对应的操作系统版本选择安装包即可。
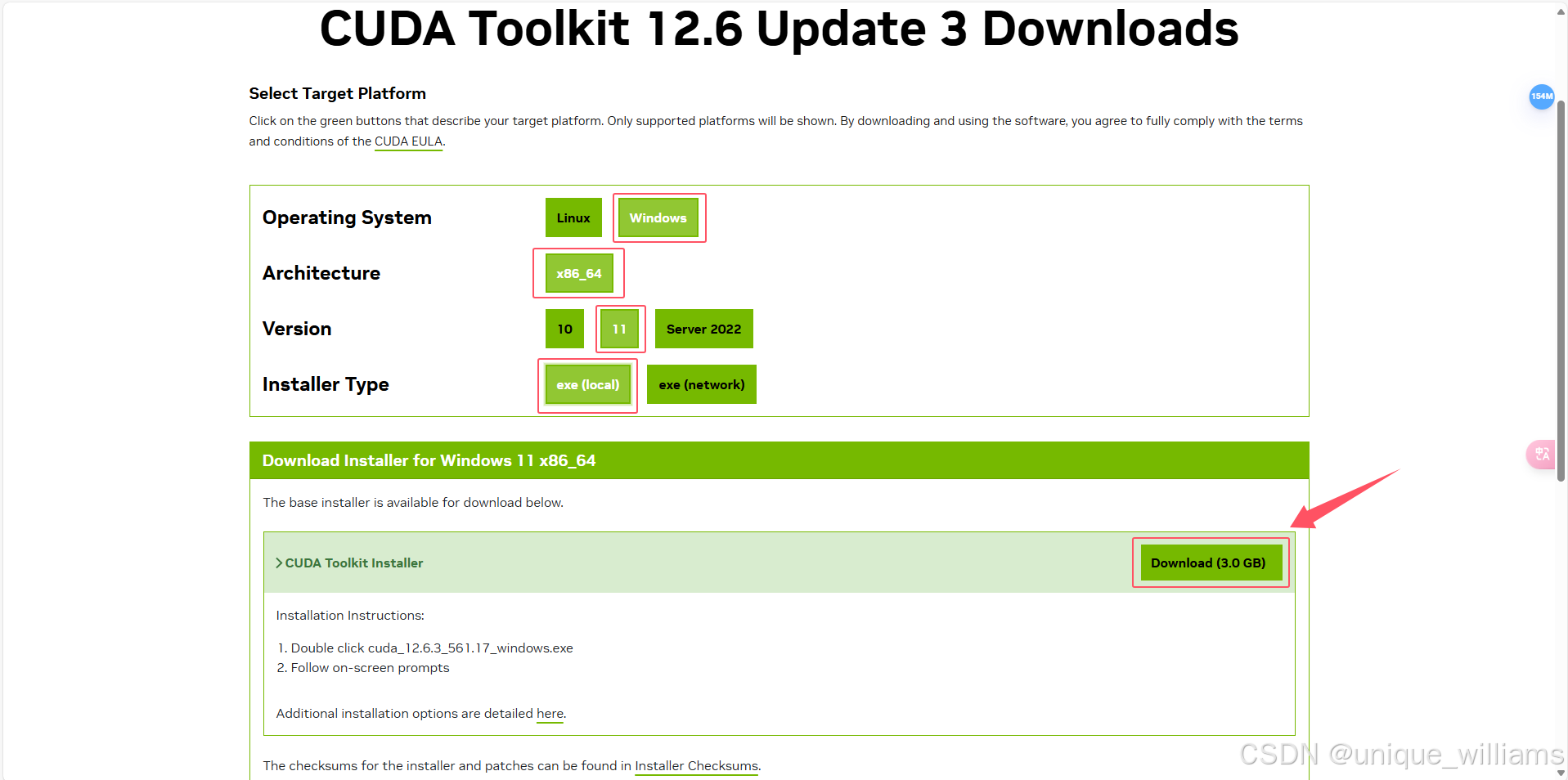
双击安装包,安装在自定义的目录文件夹下(我的C盘比较大,就直接装C盘上了)
注意,此处的 CUDA 安装地址需要提前拷贝,后面安装 cudnn 时需要用到。
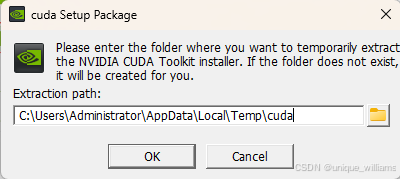
选择“精简”模式,接下来一直点“下一步”即可。
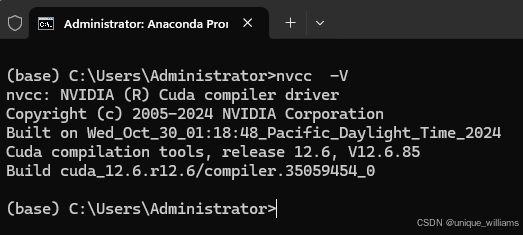
查看是否安装成功,在命令行输入指令。
nvcc -V出现如下的输出证明安装成功。
(3)安装 CuDNN(cuda加速器)
官网(CUDA深度神经网络(cuDNN)|NVIDIA开发者 --- CUDA Deep Neural Network (cuDNN) | NVIDIA Developer)
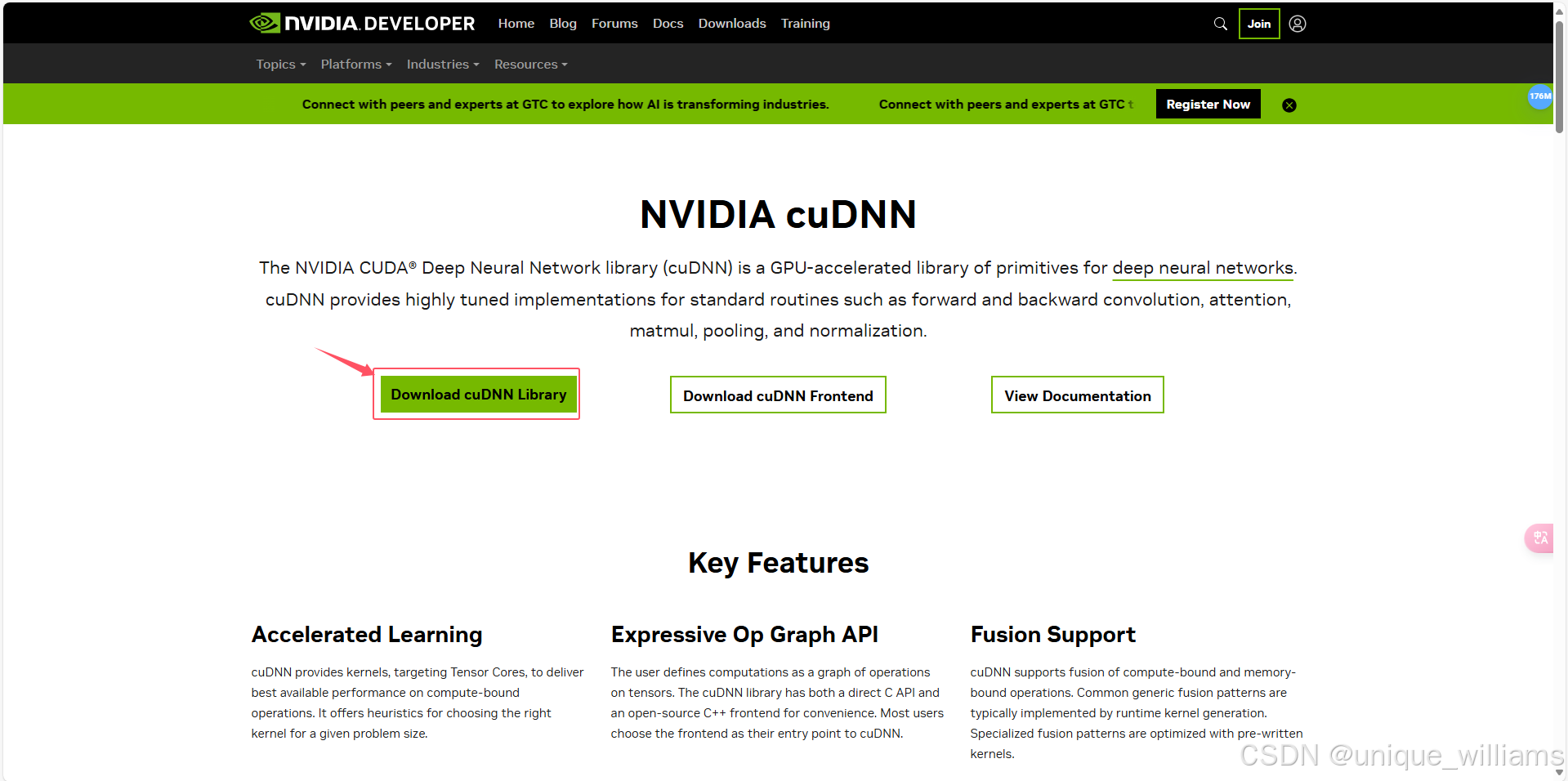
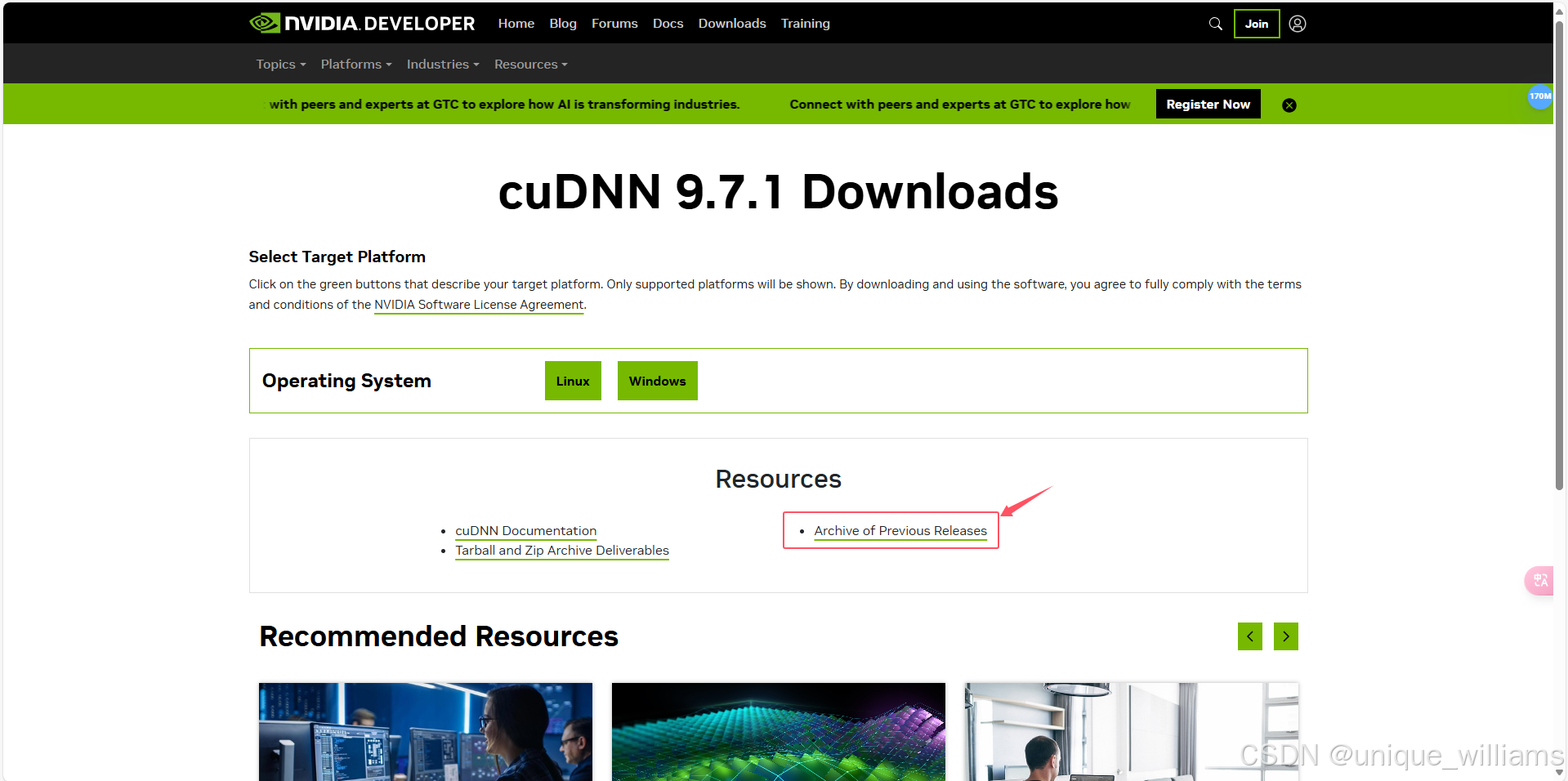

按照上方流程下载压缩包或安装包都可以,解压后将文件移动到 CUDA 安装路径下,就安装完成啦~
(4)安装PyTorch-GPU
(1)激活虚拟环境:打开先前安装 PyTorch-CPU 时创建的虚拟环境
conda activate cvtest

(2)安装PyTorch(GPU):使用pip安装 PyTorch 。注意请根据需求,选择对应的 GPU 版本,因为我安装的 CUDA 版本为12.6,因而按下方选择。
官网查看:PyTorch --- PyTorch
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126当然此处可以使用清华镜像源加速下载。
pip3 install torch torchvision torchaudio --index-url https://pypi.tuna.tsinghua.edu.cn/simple
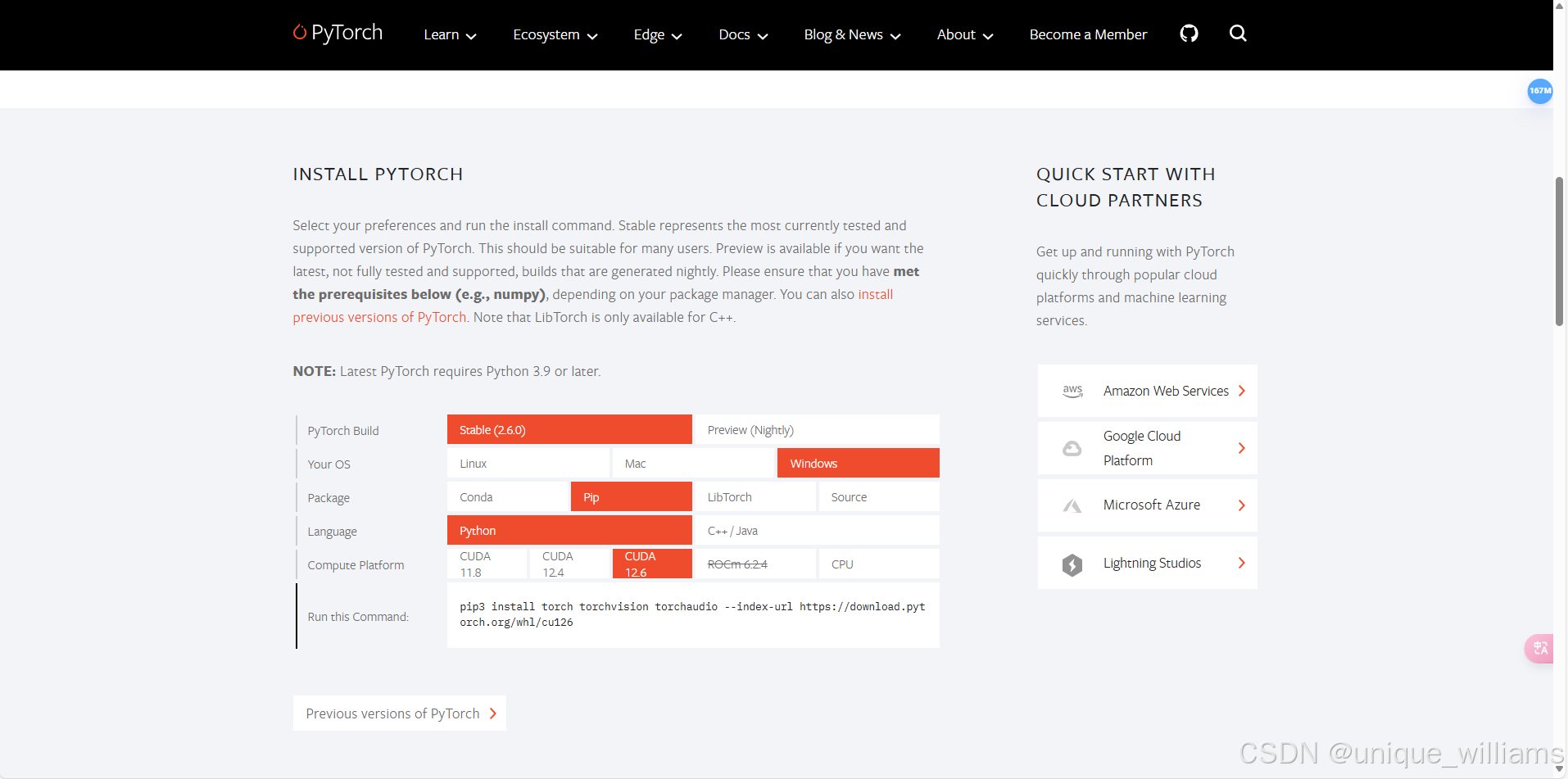
嘿嘿,相信细心的小伙伴要问了,为什么这里使用清华镜像替代没有标注 CUDA 版本呢?
这是因为在安装时,会自动安装兼容机器 CUDA 版本的 PyTorch ,从而能够利用 GPU 提升计算性能。
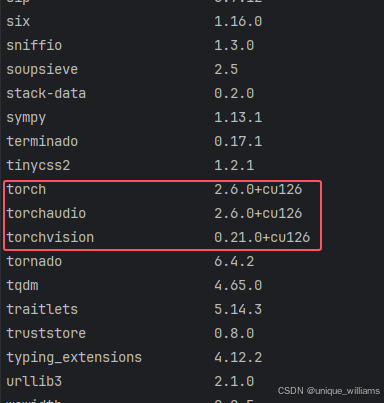
(5)检查是否安装成功
方法一:进入对应的虚拟环境输入
pip list当列表中出现如下的版本代表 PyTorch 的 CPU 和 GPU 版本都已安装成功啦~
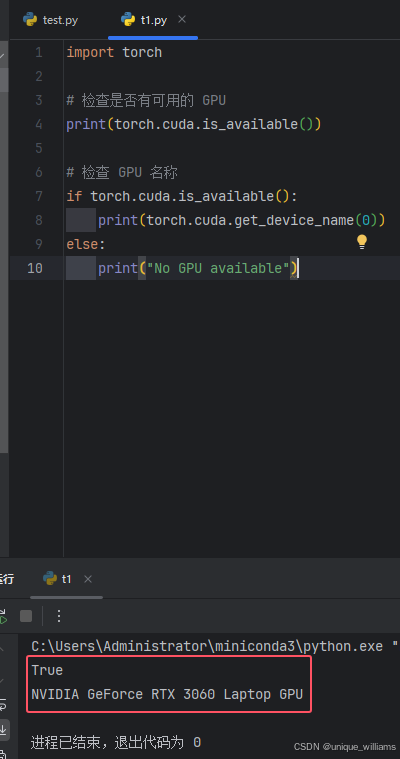
方法二:进入虚拟环境下的 Python 编译器,输入下方代码
import torch # 检查是否有可用的 GPU print(torch.cuda.is_available()) # 检查 GPU 名称 if torch.cuda.is_available(): print(torch.cuda.get_device_name(0)) else: print("No GPU available")若返回 True 和对应的 GPU 型号时,代表 GPU 版本安装成功啦~
5,OpenCV 库下载
(1)安装OpenCV库:
Python 安装 OpenCV 库相当简单,只需要在对应的虚拟环境中使用 pip 下载 opencv-python 即可。
pip install opencv-python当然你也可以使用清华镜像源进行加速。
pip install opencv-python -i https://pypi.tuna.tsinghua.edu.cn/simpleps:下方附上国内常用镜像源,需要的可以自取。
清华:https://pypi.tuna.tsinghua.edu.cn/simple
阿里云:http://mirrors.aliyun.com/pypi/simple/
中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple/
华中理工大学:http://pypi.hustunique.com/
山东理工大学:http://pypi.sdutlinux.org/
豆瓣:http://pypi.douban.com/simple/
(2)检查是否安装成功
在对应虚拟环境中打开 python 编译器,导入 cv2 包,只要不报错就安装成功啦~
import cv2如果安装失败可以参考下方博客:OpenCV-python安装教程_opencv python安装-CSDN博客
(三)定义超参数
超参数,可以理解成人为设定的全局变量。考虑到有些人使用的不是GPU,故而在设备选择时设置参数会自动选择设备。
# 定义超参数
BATCH_SIZE = 16 # 每批处理的数据
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
EPOCHS = 10 # 训练数据集轮次二、数据集下载与导入
(一)MNIST 数据集基本介绍
MNIST 数据集是一个大型手写数据库,由 LeCun 等人将其进行归一化和尺寸调整后得到的 28 * 28 的灰度图像。

MNIST 数据集总共包含两个子数据集:一个训练数据集和一个测试数据集。分别包含 60k 和 10k 的 28 * 28 的灰度图像。文件只能通过编程阅读,可以直接调用 PyTorch 的 torchvision.datasets.MINIST API接口读取。
MNIST训练集图像、训练集标签、测试集图像和测试及标签如下表:
| 数据集 | MNIST中的文件名 | 下载地址 | 文件大小 |
| 训练集图像 | train-images-idx3-ubyte.gz | https://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz | 9,681 kb |
| 训练集标签 | train-labels-idx1-ubyte.gz | https://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz | 29 kb |
|
测试集图像 |
t10k-images-idx3-ubyte.gz | https://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz | 1,611 kb |
| 测试集标签 | t10k-labels-idx1-ubyte.gz | https://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz | 5 kb |
(二)读取 MNIST 数据集
由于 MNIST 只能通过编程阅读,下方将采用直接调用 API 的形式直接读取并加载数据集。
1、归一化:softmax归一化指数函数(https://blog.csdn.net/lz_peter/article/details/84574716),其中 mean 均值为:0.1307,std 标准差为:0.3081。
# 定义pipeline
pipeline = transforms.Compose([
transforms.ToTensor(), # 将图片转换成tensor
transforms.Normalize((0.1307, ), (0.3081, )) # 正则化,降低模型复杂度(过拟合)
])2、下载数据集:其中 root 为数据集存放路径,train=True 为训练集,train=False 为测试集。
train_set = datasets.MNIST('data',train=True,download=True,transform=pipeline)
test_set = datasets.MNIST('data',train=False,download=True,transform=pipeline)3、加载数据集:实例化一个dataset,使用Dataloader包起来,载入数据集。BATCH_SIZE为超参数,详见 1.3 ,shuffle = True 即打乱数据集。
train_loader = DataLoader(train_set, batch_size=BATCH_SIZE, shuffle=True)
test_loader = DataLoader(test_set, batch_size=BATCH_SIZE, shuffle=True)4、查看是否能正常读取:插入代码显示MNIST中的图片,此处'data/MNIST/raw/t10k-images-idx3-ubyte',替换成数据集安装的位置,如果下载数据集的过程跟第二步一致,则无需变更。
with open('data/MNIST/raw/t10k-images-idx3-ubyte','rb') as f:
image_data = f.read(16 + 784)[16:]
img_np = np.frombuffer(image_data, dtype=np.uint8).reshape(28, 28)
cv2.imshow('digit.jpg',img_np)
cv2.waitKey(0)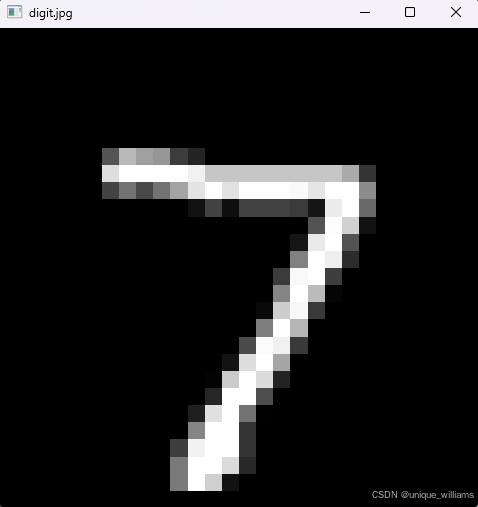
当然你也可以调用 matplotlib 更美观地查看图片。
三、MNIST 识别流程及专业名词解释
(一)手写体识别流程
(1)定义超参数 ;
(2)构建transforms,主要是对图像做变换;
(3)下载、加载数据集 MNIST;
(4)构建网络模型;
(5)定义训练方法;
(6)定义测试方法;
(7)开始训练模型,输出预测结果;
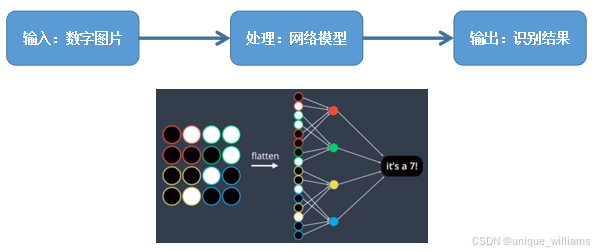
(二)专业名词解释
(1)参数与超参数
参数:模型f(x, θ)中的θ 称为模型的参数,可以通过优化算法进行学习。
超参数:用来定义模型结构或优化策略。
(2)batch_size 批处理
每次处理的数据数量。
(3)epoch 轮次
把一个数据集,循环运行几轮。
(4)transforms 变换
主要是将图片转换为tensor,旋转图片,以及正则化。
(5)nomalize 正则化
模型出现过拟合现象时,降低模型复杂度。
(6)卷积层:
由卷积核构建,卷积核简称为卷积,也称为滤波器。卷积的大小可以在实际需要时自定义其长和宽(1*1, 3*3, 5*5)。
nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding)
参数:
- in_channels:输入通道
- out_channels:输出通道
- kernel_size:卷积核大小
- stride:步长
- padding:填充
(7)池化层:
对图片进行压缩(降采样)的一种方法,如max pooling, average pooling等。
nn.MaxPool2d(input, kernel_size, stride, padding)
参数:
- input:输入
- kernel_size:卷积核大小
- stride:步长
- padding:填充
(8)激活层:
激活函数的作用就是,在所有的隐藏层之间添加一个激活函数,这样的输出就是一个非线性函数了,因而神经网络的表达能力更加强大了。
该处使用了ReLU激活函数,全名线性整流函数,又称修正线性单元,指代以斜坡函数为代表的非线性函数。
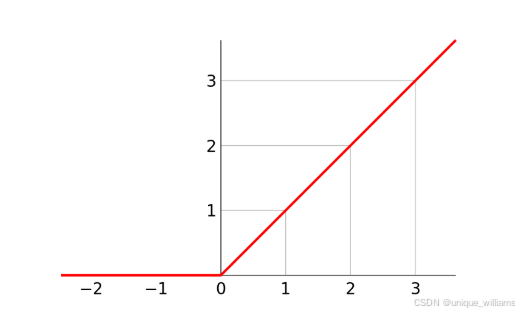
nn.ReLU()
(9)损失函数:
在深度学习中,损失反映模型最后预测结果与实际真值之间的差距,可以用来分析训练过程的好坏、模型是否收敛等,例如均方损失、交叉熵损失等。
(10)前向传播:
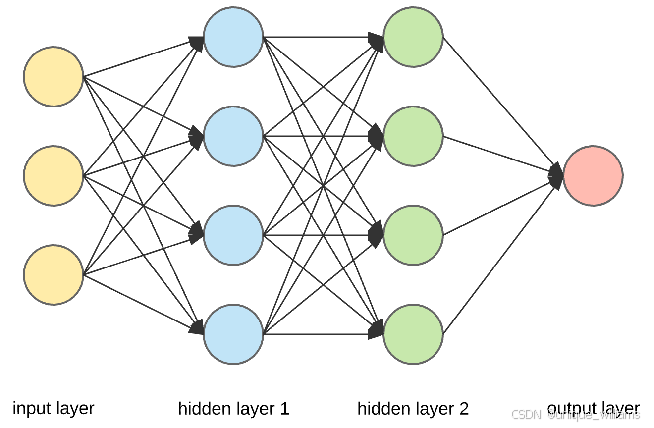
(11)反向传播
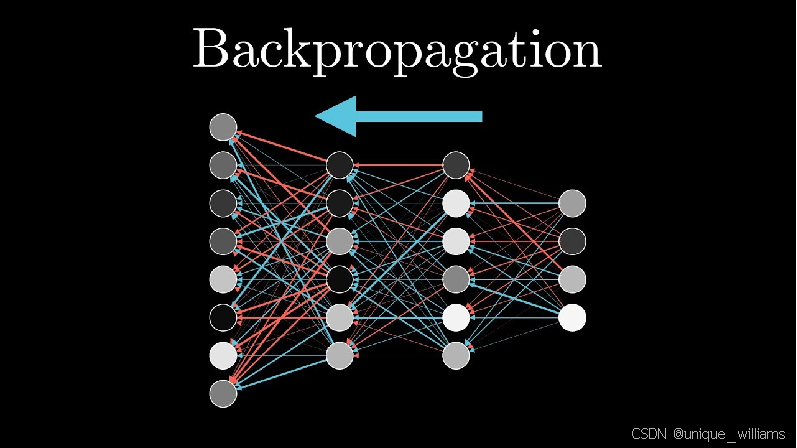
参考博客:https://blog.csdn.net/weixin_38347387/article/details/82936585
(12)梯度下降
四、构建网络模型(CNN)
概念模型如图所示:
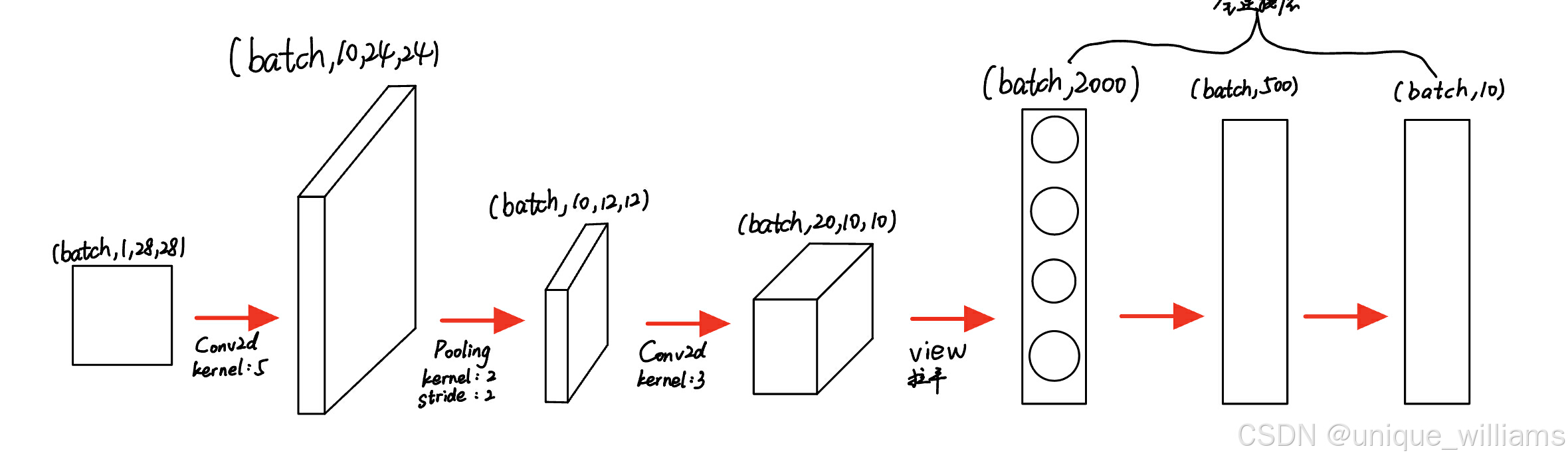
比如输入一个手写数字图像,它的维度为(batch,1,28,28)即单通道高宽分别为28像素。
- 首先通过一个卷积核为5×5的卷积层,其通道数从1变为10,高宽分别为24像素;
- 然后通过一个卷积核为2×2的最大池化层,通道数不变,高宽变为一半,即维度变成(batch,10,12,12);
- 然后再通过一个卷积核为3×3的卷积层,其通道数从10变为20,高宽分别为10像素;
- 之后将其view展平,使其维度变为2000之后进入全连接层,用线性函数将其输出为10类,即“0-9”10个数字。
构建网络代码如下:
class Digit(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=3)
self.fc1 = nn.Linear(20*10*10, 500)
self.fc2 = nn.Linear(500, 10)
def forward(self,x):
input_size = x.size(0) # batch_size * 1 * 28 * 28
x = self.conv1(x) # 输入:batch*1*28*28,输出:batch*10*24*24(28-5+1)
x = F.relu(x) # 激活函数
x = F.max_pool2d(x,2,2) # 池化层(输入:batch*10*24*24,输出:batch*10*12*12)
x = self.conv2(x) # 输入:batch*10*12*12,输出:batch*20*10*10
x = F.relu(x)
x = x.view(input_size,-1) # 拉平,-1 自动计算维度,20*10*10 = 2000
x = self.fc1(x) # 输入:batch * 2000,输出:batch * 500
x = F.relu(x)
x = self.fc2(x) # 输出:batch*10
output = F.log_softmax(x, dim=1) # 计算分类后,每个数字的概率值
return output五、定义损失函数和优化器
损失函数使用交叉熵损失
loss = F.cross_entropy(output, target)优化器使用Adam优化器
optimizer = optim.Adam(model.parameters())六、定义训练方法
(一)关键流程说明
1、设备部署
- 使用
.to(device)将数据迁移到 GPU/CPU 设备,利用硬件加速计算
data, target = data.to(device), target.to(device)2、梯度管理
optimizer.zero_grad()确保每个batch的梯度独立计算loss.backward()自动计算梯度(基于计算图的反向传播)
3、优化机制
- 使用
optimizer.step()执行实际参数更新 cross_entropy适合分类任务,结合 LogSoftmax 与 NLLLoss
4、训练监控
- 每 3000 个 batch 输出当前损失值(平衡日志信息量与训练效率)
model.train()确保 Dropout / BatchNorm 等训练专用层的正确行为
optimizer.step()
if batch_idx % 3000 == 0:
print('Train Epoch : {} \t Loss : {:.6f}'.format(epoch, loss.item()))(二)功能特性
- 支持任何继承
torch.nn.Module的模型结构 - 可无缝对接不同的优化器( Adam / SGD / RMSprop 等)
- 自动适应 GPU 加速训练与普通 CPU 训练环境
- 采用 batch 梯度下降策略,适合大规模数据集训练
代码如下:
def train_model(model, device, train_loader, optimizer, epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
# 部署到device上去
data, target = data.to(device), target.to(device)
# 梯度初始化
optimizer.zero_grad()
# 预测
output = model(data)
# 计算损失
loss = F.cross_entropy(output, target)
# 找到概率最大的下表
pred = output.max(1, keepdim=True)[1]
# 反向传播
loss.backward()
# 参数优化
optimizer.step()
if batch_idx % 3000 == 0:
print('Train Epoch : {} \t Loss : {:.6f}'.format(epoch, loss.item()))七、定义测试方法
(一)核心机制说明
1、验证模式设置
model.eval():冻结 Dropout 层(保持全连接状态)和固定 BatchNorm 层的统计量with torch.no_grad():禁用梯度追踪,节省约30%显存占用
2、预测结果解析
max(1, keepdim=True)[1]:获取每个样本最大概率对应的类别索引(维度保)view_as(pred):确保标签张量与预测结果的形状匹配(便于逐元素比较)
3、精度计算流程
- 损失累计时使用
.item()剥离梯度信息,避免显存泄漏 - 正确率计算基于全量测试数据:正确样本数总样本数×100%总样本数正确样本数×100%
4、关键数学计算
# 损失计算展开说明(交叉熵)
loss = -sum( target_onehot * log_softmax(output) ) / batch_size
# 准确率优化方向:
Accuracy = where( argmax(output) == target ).sum() / N(二)差异化特性
1、与训练模式的三大差异
- 不执行反向传播(
loss.backward()缺失) - 优化器步骤禁用(
optimizer.step()缺失) - 使用
.eval()代替.train()模式
2、工程优化特点
- 内存优化策略:梯度追踪禁用
- 结果稳定性:全程使用完整测试集评估
- 指标合理性:平均损失使不同batch_size的评估结果具有可比性
(三)附加说明
1、可扩展性:
- 支持添加TOP-K准确率计算
- 可集成混淆矩阵等高级评估指标
- 能够融合TensorBoard等可视化监控工具
代码如下:
def test_mode(model, device, test_loader):
# 模型验证
model.eval()
# 统计正确率
correct = 0
# 测试损失
test_loss = 0.0
with torch.no_grad(): # 不会计算梯度,也不会进行反向传播
for data,target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += F.cross_entropy(output, target).item()
pred = output.max(1, keepdim=True)[1]
# pred = torch.max(output, dim=1)
# pred = output.argmax(dim=1)
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print('Test —— Average Loss: {:.4f}, Accuracy : {:.3f}\n'.format(test_loss, 100.0*correct/len(test_loader.dataset)))八、调用六七步定义的函数进行训练
主函数:共进行10轮训练,每训练一次,进行测试计算准确度。
for epoch in range(1,EPOCHS+1):
train_model(model, DEVICE, train_loader, optimizer, epoch)
test_mode(model, DEVICE, test_loader)九、结果与分析
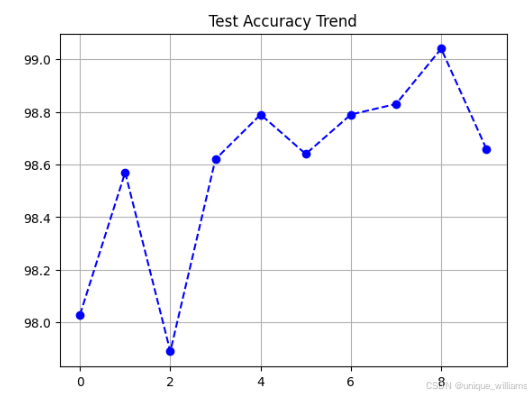
下方为训练集和测试集上的损失值和识别准确率的输出结果。
可以看到一共进行10轮次的训练和测试:每一轮的训练中,每300小批量数据输出一次损失值和准确率;每一轮训练结束后进行一次测试,并打印其在测试集上的准确率。
10轮后,在在测试集上的准确率达到99.040%,其中测试集上准确率如下图所示。
Train Epoch : 1 Loss : 2.303364 Train Epoch : 1 Loss : 0.000179 Test —— Average Loss: 0.0040, Accuracy : 98.030 % Train Epoch : 2 Loss : 0.001320 Train Epoch : 2 Loss : 0.002481 Test —— Average Loss: 0.0030, Accuracy : 98.570 % Train Epoch : 3 Loss : 0.003210 Train Epoch : 3 Loss : 0.016292 Test —— Average Loss: 0.0051, Accuracy : 97.890 % Train Epoch : 4 Loss : 0.000144 Train Epoch : 4 Loss : 0.001467 Test —— Average Loss: 0.0031, Accuracy : 98.620 % Train Epoch : 5 Loss : 0.000016 Train Epoch : 5 Loss : 0.000018 Test —— Average Loss: 0.0035, Accuracy : 98.790 % Train Epoch : 6 Loss : 0.000023 Train Epoch : 6 Loss : 0.000001 Test —— Average Loss: 0.0048, Accuracy : 98.640 % Train Epoch : 7 Loss : 0.000044 Train Epoch : 7 Loss : 0.009669 Test —— Average Loss: 0.0040, Accuracy : 98.790 % Train Epoch : 8 Loss : 0.000005 Train Epoch : 8 Loss : 0.000104 Test —— Average Loss: 0.0039, Accuracy : 98.830 % Train Epoch : 9 Loss : 0.000023 Train Epoch : 9 Loss : 0.000004 Test —— Average Loss: 0.0035, Accuracy : 99.040 % Train Epoch : 10 Loss : 0.000029 Train Epoch : 10 Loss : 0.000000 Test —— Average Loss: 0.0054, Accuracy : 98.660 %
十、完整代码
# 导入必要的库
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
import cv2
import numpy as np
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
# 定义超参数
BATCH_SIZE = 16 # 每批处理的数据
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
EPOCHS = 10 # 训练数据集轮次
# 定义pipeline
pipeline = transforms.Compose([
transforms.ToTensor(), # 将图片转换成tensor
transforms.Normalize((0.1307, ), (0.3081, )) # 正则化,降低模型复杂度(过拟合)
])
# 下载数据集
train_set = datasets.MNIST('data',train=True,download=True,transform=pipeline)
test_set = datasets.MNIST('data',train=False,download=True,transform=pipeline)
train_loader = DataLoader(train_set, batch_size=BATCH_SIZE, shuffle=True)
test_loader = DataLoader(test_set, batch_size=BATCH_SIZE, shuffle=True)
# 插入代码显示MNIST中的图片
with open('data/MNIST/raw/t10k-images-idx3-ubyte','rb') as f:
image_data = f.read(16 + 784)[16:]
img_np = np.frombuffer(image_data, dtype=np.uint8).reshape(28, 28)
cv2.imwrite('digit.jpg',img_np)
class Digit(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=3)
self.fc1 = nn.Linear(20*10*10, 500)
self.fc2 = nn.Linear(500, 10)
def forward(self,x):
input_size = x.size(0) # batch_size * 1 * 28 * 28
x = self.conv1(x) # 输入:batch*1*28*28,输出:batch*10*24*24(28-5+1)
x = F.relu(x) # 激活函数
x = F.max_pool2d(x,2,2) # 池化层(输入:batch*10*24*24,输出:batch*10*12*12)
x = self.conv2(x) # 输入:batch*10*12*12,输出:batch*20*10*10
x = F.relu(x)
x = x.view(input_size,-1) # 拉平,-1 自动计算维度,20*10*10 = 2000
x = self.fc1(x) # 输入:batch * 2000,输出:batch * 500
x = F.relu(x)
x = self.fc2(x) # 输出:batch*10
output = F.log_softmax(x, dim=1) # 计算分类后,每个数字的概率值
return output
# 定义优化器
model = Digit().to(DEVICE)
optimizer = optim.Adam(model.parameters())
# 定义训练方法
def train_model(model, device, train_loader, optimizer, epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
# 部署到device上去
data, target = data.to(device), target.to(device)
# 梯度初始化
optimizer.zero_grad()
# 预测
output = model(data)
# 计算损失
loss = F.cross_entropy(output, target)
# 找到概率最大的下表
pred = output.max(1, keepdim=True)[1]
# 反向传播
loss.backward()
# 参数优化
optimizer.step()
if batch_idx % 3000 == 0:
print('Train Epoch : {} \t Loss : {:.6f}'.format(epoch, loss.item()))
# 定义测试方法
def test_mode(model, device, test_loader):
# 模型验证
model.eval()
# 统计正确率
correct = 0
# 测试损失
test_loss = 0.0
with torch.no_grad(): # 不会计算梯度,也不会进行反向传播
for data,target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += F.cross_entropy(output, target).item()
pred = output.max(1, keepdim=True)[1]
# pred = torch.max(output, dim=1)
# pred = output.argmax(dim=1)
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print('Test —— Average Loss: {:.4f}, Accuracy : {:.3f} %\n'.format(test_loss, 100.0*correct/len(test_loader.dataset)))
return 100.0 * correct / len(test_loader.dataset)
acc_list_test = []
for epoch in range(1,EPOCHS+1):
train_model(model, DEVICE, train_loader, optimizer, epoch)
acc = test_mode(model, DEVICE, test_loader)
acc_list_test.append(acc)
plt.figure(dpi=100) # 设置图像清晰度
plt.plot(acc_list_test, marker='o', linestyle='--', color='b')
plt.title('Test Accuracy Trend')
plt.grid(True)客官,看到这啦能否点个赞再走~

「智能机器人开发者大赛」官方平台,致力于为开发者和参赛选手提供赛事技术指导、行业标准解读及团队实战案例解析;聚焦智能机器人开发全栈技术闭环,助力开发者攻克技术瓶颈,促进软硬件集成、场景应用及商业化落地的深度研讨。 加入智能机器人开发者社区iRobot Developer,与全球极客并肩突破技术边界,定义机器人开发的未来范式!
更多推荐


 70
70 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)