FCOS 论文结合 MMDetection 中 fcos_head 代码解读
一、背景
(一)FCOS 是什么
FCOS 是一个全卷积的单阶段的无锚框目标检测器
- 全卷积:都是卷基层,无全连接层
- 单阶段:直接从输入图像的特征图上预测类别、边界框;而不需要先生成候选框再分类
(二)基于锚框的检测算法的缺点
- 检测性能对锚框的大小、纵横比、数量都很敏感 ---> 因此,需要仔细调这些超参数
- 每个锚框的大小、纵横比都是固定的 ---> 当一张图像中的不同物体形状变化比较大时,不好处理
而对于新任务,就又需要重新设计锚框 ---> 泛化能力差 - 为了提高召回率,会生成大量的负样本 ---> 会导致正负样本极度不平衡
- 锚框还涉及到复杂的计算,如需要每一个锚框和 gt_box,计算 IOU
二、FCOS 论文 + fcos_head 代码
(一)FCOS 整体框架
首先,输入 800*1024 的图像,经过 backbone,得到特征图 P3,P4,P5,如 P3 具有较精准的位置信息,但是语义信息不是那么丰富,所以将高层次的语义信息 P4 融合到 P3
至于 P6,P7继续下采样,是为了检测更大尺度的物体
对于不同尺度的特征图,使用共享的检测头 Head 进行分类和回归
Backbone 的作用是提取图像特征。FPN主要做特征融合。Head主要做最后的分类和回归,并且FCOS 的最后输出有三条分支:1. Classification 2. Center-ness 3. Regression。
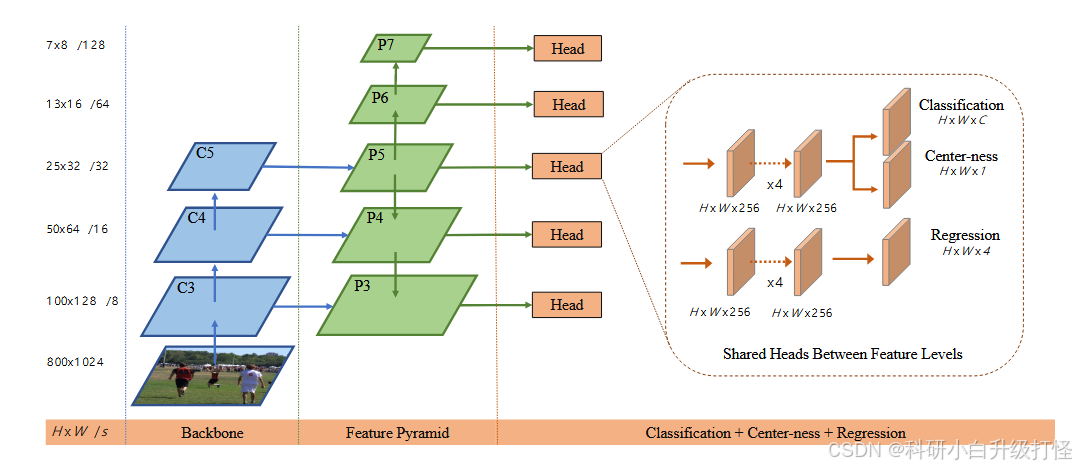
(二)分类和回归的具体做法
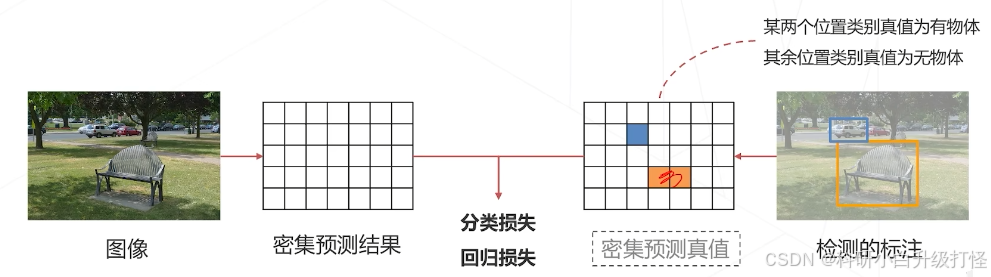
首先要明确的是:关于输入图像会生成一张密集的真值预测(输入图像上标准好 ground truth 框,过卷积网络,得到密集预测的真值),然后是密集预测的结果和密集预测的真值进行分类和回归损失,就是在图征途上做的,而不是要将特征图上的采样点映射回原图感受野中心
但注意:训练时,都在特征图上,而推理时,是在原图上比较,所以要得到相对于原图的预测框(预测的边界框 * 步长)
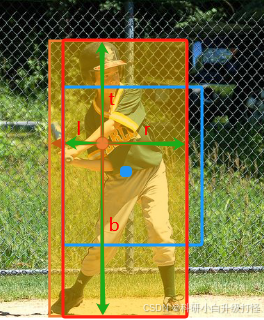
(1)计算 (l, r, t, b)
比如图中的橙色圆点是特征图上的某个采样点,坐标为 (xs, ys),然后和特征图上的 ground truth 边界框算偏移量,即回归预测的一个 4D 张量(l, r, t, b)
其中 ground truth 边界框的坐标为:左上角坐标(gt_bboxes[..., 0],gt_bboxes[..., 1]),右下角坐标(gt_bboxes[..., 2],gt_bboxes[..., 3])

(l, r, t, b)计算:
left = xs - gt_bboxes[..., 0]
right = gt_bboxes[..., 2] - xs
top = ys - gt_bboxes[..., 1]
bottom = gt_bboxes[..., 3] - ys
bbox_targets = torch.stack((left, top, right, bottom), -1)(2)区分正负样本
- 如下面左图中蓝色圆点是 ground truth 边界框的中心坐标 ,即 (center_xs,center_ys)
- 计算特征金字塔每个层级的采样点步长 stride
- 根据 ground truth 边界框中心坐标和步长 stride ,计算出蓝色的边界框,蓝色边界框坐标为:左上角(x_mins,y_mins),右下角(x_maxs,y_maxs)
注:P3 层到 P7 层的回归范围依次是(-1, 64), (64, 128), (128, 256), (256, 512),(512, INF),属于回归范围即:(cb_dist_left,cb_dist_right,cb_dist_top,cb_dist_bottom) 中的最大值属于当前特征图的回归范围内 - 为了保证所有采样点都在 ground truth 边界框内,在算出蓝色边界框之后,又更新了 ground truth 边界框为红色的框,其左上角坐标更新为(center_gts[..., 0],center_gts[..., 1]),右下角坐标更新为(center_gts[..., 2],center_gts[..., 3])
- 根据红色的 ground truth 边界框去计算新的回归张量 (cb_dist_left,cb_dist_right,cb_dist_top,cb_dist_bottom)
- 如果绿色箭头,即 (cb_dist_left,cb_dist_right,cb_dist_top,cb_dist_bottom) 中的最小值大于 0 ,则说明此采样点在 ground truth 边界框(红色边界框)内
而落在此红框内并且属于回归范围内的就叫正样本



stride 计算:
stride = center_xs.new_zeros(center_xs.shape)
lvl_begin = 0
for lvl_idx, num_points_lvl in enumerate(num_points_per_lvl):
lvl_end = lvl_begin + num_points_lvl
lvl_end = lvl_begin + num_points_lvl。
stride[lvl_begin:lvl_end] = self.strides[lvl_idx] * radius # radius 是一个超参数,表示中心采样的半径大小。
lvl_begin = lvl_end(x_mins,y_mins),(x_maxs,y_maxs)坐标计算:
x_mins = center_xs - stride
y_mins = center_ys - stride
x_maxs = center_xs + stride
y_maxs = center_ys + stride红色 ground truth 边界框坐标(center_gts[..., 0],center_gts[..., 1])(center_gts[..., 2],center_gts[..., 3]) 计算:
center_gts[..., 0] = torch.where(x_mins > gt_bboxes[..., 0],
x_mins, gt_bboxes[..., 0])
center_gts[..., 1] = torch.where(y_mins > gt_bboxes[..., 1],
y_mins, gt_bboxes[..., 1])
center_gts[..., 2] = torch.where(x_maxs > gt_bboxes[..., 2],
gt_bboxes[..., 2], x_maxs)
center_gts[..., 3] = torch.where(y_maxs > gt_bboxes[..., 3],
gt_bboxes[..., 3], y_maxs)(cb_dist_left,cb_dist_right,cb_dist_top,cb_dist_bottom) 计算:
cb_dist_left = xs - center_gts[..., 0]
cb_dist_right = center_gts[..., 2] - xs
cb_dist_top = ys - center_gts[..., 1]
cb_dist_bottom = center_gts[..., 3] - ys
center_bbox = torch.stack((cb_dist_left, cb_dist_top, cb_dist_right, cb_dist_bottom), -1)(3)处理重叠边界框问题
如下图采样点落在了两个 ground truth 边界框内,我们首先使用 FPN 金字塔结构处理这种混淆问题,P3 层到 P7 层的回归范围依次是(-1, 64), (64, 128), (128, 256), (256, 512),(512, INF),因此让每层特征图只检测其对应尺度的物体,这样可以很大程度上的解决边界框混淆问题
但如果还存在一个采样点对应多个 ground truth 边界框,则选择边界框面积最小的作为其 ground truth。

对于混淆问题,选择面积最小的 ground truth 边界框:
max_regress_distance = bbox_targets.max(-1)[0]
inside_regress_range = (
(max_regress_distance >= regress_ranges[..., 0])
& (max_regress_distance <= regress_ranges[..., 1]))
areas[inside_gt_bbox_mask == 0] = INF
areas[inside_regress_range == 0] = INF
min_area, min_area_inds = areas.min(dim=1)
labels = gt_labels[min_area_inds]
labels[min_area == INF] = self.num_classes # set as BG
bbox_targets = bbox_targets[range(num_points), min_area_inds](4)计算中心性 centerness
因为会在远离目标对象中心的位置生成许多低质量的预测边界框,所以引入了 centerness 分支来抑制低质量的预测边界框。
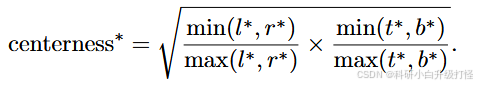

centerness 计算:
其中 pos_bbox_targets[:, [0, 2]] ,存的就是 (cb_dist_left,cb_dist_right,cb_dist_top,cb_dist_bottom),即绿色箭头长度
left_right = pos_bbox_targets[:, [0, 2]]
top_bottom = pos_bbox_targets[:, [1, 3]]
if len(left_right) == 0:
centerness_targets = left_right[..., 0]
else:
centerness_targets = (
left_right.min(dim=-1)[0] / left_right.max(dim=-1)[0]) * (
top_bottom.min(dim=-1)[0] / top_bottom.max(dim=-1)[0])(三)损失函数
FCOS 损失函数 = 分类损失 + 回归损失 + 中心度损失,其中回归损失和中心度损失只对正样本计算
- 分类损失:BCE(Binary Cross Entropy)交叉熵损失 + FocalLoss
- 回归损失:GIoU Loss GIoU Loss = 1 - GIoU
- 中心度损失:BCE
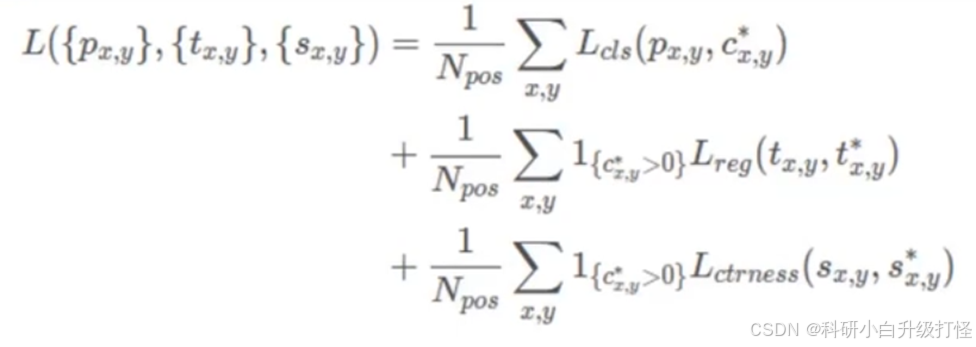

IOU、GIOU 计算
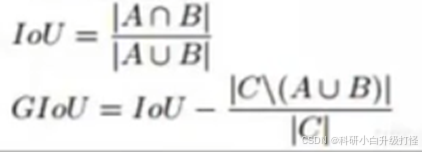
损失函数计算:
bg_class_ind = self.num_classes
pos_inds = ((flatten_labels >= 0)
& (flatten_labels < bg_class_ind)).nonzero().reshape(-1)
num_pos = torch.tensor(
len(pos_inds), dtype=torch.float, device=bbox_preds[0].device)
num_pos = max(reduce_mean(num_pos), 1.0)
loss_cls = self.loss_cls( # 计算分类损失
flatten_cls_scores, flatten_labels, avg_factor=num_pos)
# 计算回归损失和中心性损失。
if getattr(self.loss_cls, 'custom_accuracy', False):
acc = self.loss_cls.get_accuracy(flatten_cls_scores,
flatten_labels)
losses.update(acc)
pos_bbox_preds = flatten_bbox_preds[pos_inds] pos_bbox_targets 和 pos_centerness_targets。
pos_centerness = flatten_centerness[pos_inds]
pos_bbox_targets = flatten_bbox_targets[pos_inds]
pos_centerness_targets = self.centerness_target(pos_bbox_targets)
# centerness weighted iou loss
centerness_denorm = max(
reduce_mean(pos_centerness_targets.sum().detach()), 1e-6)
# 处理了正样本的边界框回归损失和中心性损失的计算,为了避免在没有正样本的情况下出现除零错误。
if len(pos_inds) > 0:
pos_points = flatten_points[pos_inds]
pos_decoded_bbox_preds = self.bbox_coder.decode(
pos_points, pos_bbox_preds)
pos_decoded_target_preds = self.bbox_coder.decode(
pos_points, pos_bbox_targets)
loss_bbox = self.loss_bbox(
pos_decoded_bbox_preds,
pos_decoded_target_preds,
weight=pos_centerness_targets,
avg_factor=centerness_denorm)
loss_centerness = self.loss_centerness(
pos_centerness, pos_centerness_targets, avg_factor=num_pos)
else:
loss_bbox = pos_bbox_preds.sum()
loss_centerness = pos_centerness.sum()
losses['loss_cls'] = loss_cls
losses['loss_bbox'] = loss_bbox
losses['loss_centerness'] = loss_centerness
「智能机器人开发者大赛」官方平台,致力于为开发者和参赛选手提供赛事技术指导、行业标准解读及团队实战案例解析;聚焦智能机器人开发全栈技术闭环,助力开发者攻克技术瓶颈,促进软硬件集成、场景应用及商业化落地的深度研讨。 加入智能机器人开发者社区iRobot Developer,与全球极客并肩突破技术边界,定义机器人开发的未来范式!
更多推荐

 51
51 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)