具身智能工作汇总以及细节方向
具身智能(Embedded AI)对于实现通用人工智能(AGI)至关重要,是连接网络空间和物理世界的各种应用的基础。最近,多模态大模型(MLM)和世界模型(WMs)的出现因其卓越的感知、交互和推理能力而引起了人们的广泛关注,使其成为具身智能体大脑的一种有前景的架构。这里我们主要分析四个主要的研究目标:1)具身感知,2)具身交互,3)具身代理,4)仿真到真实的适应。其实现在主要的工作还是集中在2D场
0. 简介
具身智能(Embedded AI)对于实现通用人工智能(AGI)至关重要,是连接网络空间和物理世界的各种应用的基础。最近,多模态大模型(MLM)和世界模型(WMs)的出现因其卓越的感知、交互和推理能力而引起了人们的广泛关注,使其成为具身智能体大脑的一种有前景的架构。这里我们主要分析四个主要的研究目标:1)具身感知,2)具身交互,3)具身代理,4)仿真到真实的适应。其实现在主要的工作还是集中在2D场景下的轮式和机械臂和灵巧手上。我们会从这些方向深度了解并找到其中的共同点以及期望的方向
1. 机器人分类
Embodied agent积极与物理环境交互,涵盖了广泛的实施例,包括机器人、智能电器、智能眼镜、自动驾驶汽车等。其中,机器人是最突出的实施例之一。根据应用,机器人被设计成各种形式,以利用其硬件特性完成特定任务,如图所示。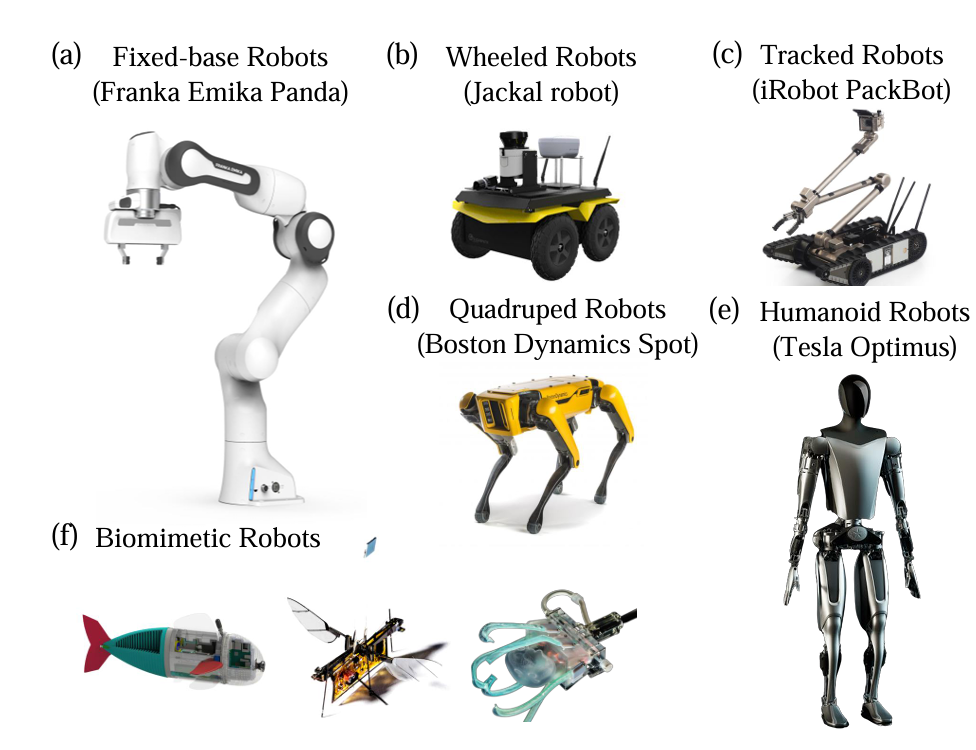
1.1 Fixed-base Robots
如图(a)所示,固定基座机器人因其紧凑性和高精度操作而广泛应用于实验室自动化、教育培训和工业制造。这些机器人具有坚固的底座和结构,可确保操作过程中的稳定性和高精度。配备高精度传感器和执行器,可实现微米级精度,使其适用于需要高精度和可重复性的任务。
1.2 Wheeled Robots and Tracked Robots
对于移动机器人来说,它们可以面对更复杂和多样化的应用场景。如图(b)所示,轮式机器人以其高效的机动性而闻名,广泛应用于物流、仓储和安全检查。轮式机器人的优点包括结构简单、成本相对较低、能源效率高、在平面上的快速移动能力。这些机器人通常配备激光雷达和摄像头等高精度传感器,实现自主导航和环境感知,使其在自动化仓库管理和检查任务中非常有效。
相比之下,履带式机器人具有强大的越野能力和高机动性,在农业、建筑和灾难恢复方面显示出巨大的潜力,如图(c)所示。轨道系统提供了更大的地面接触面积,分散了机器人的重量,降低了在泥泞和沙地等软地形中沉没的风险。
1.3 Quadruped Robots
四足机器人以其稳定性和适应性而闻名,非常适合复杂的地形探索、救援任务和军事应用。受四足动物的启发,这些机器人可以在不平坦的表面上保持平衡和机动性,如图4(d)所示。多关节设计使它们能够模仿生物运动,实现复杂的步态和姿势调整。高可调性使机器人能够自动适应不断变化的地形,提高机动性和稳定性。
1.4 Humanoid Robots
人形机器人以其类似人类的形态而闻名,在服务业、医疗保健和协作环境等领域越来越普遍。这些机器人可以模仿人类的动作和行为模式,提供个性化的服务和支持。如图(e)所示,它们灵巧的手设计使它们能够执行复杂而复杂的任务,使其有别于其他类型的机器人。
1.5 Biomimetic Robots
不同的仿生机器人通过仿真自然生物的有效运动和功能,在复杂和动态的环境中执行任务。通过仿真生物具身的形态和运动机制,这些机器人在医疗保健、环境监测和生物研究等领域显示出巨大的潜力。如图(f)所示。
2. 具身感知
未来视觉感知会体现为以视觉推理和社会智能为中心。具有具身感知的主体不太可能识别图像中的物体,必须在物理世界中移动并与环境交互。这需要对3D空间和动态环境有更深入的了解。体现感知需要视觉感知和推理,理解场景中的3D关系,并根据视觉信息预测和执行复杂的任务。
2.1 Active Visual Perception
主动视觉感知系统需要基本的能力,如状态估计、场景感知和环境探索。如图所示,这些功能在vSLAM、3D场景理解和主动探索领域得到了广泛的研究。这些研究领域有助于开发强大的主动视觉感知系统,促进复杂动态环境中的环境交互和导航。我们简要介绍了这三个组成部分,并总结了表中每个部分提到的方法。这一块的发展前景比较大,高保真的视觉构建还是比较重要的,通过各种手段来提升观测的质量,这一块重要是为了提供更精确的观测质量,不会特别面向用户端,是整个具身感知的基础。
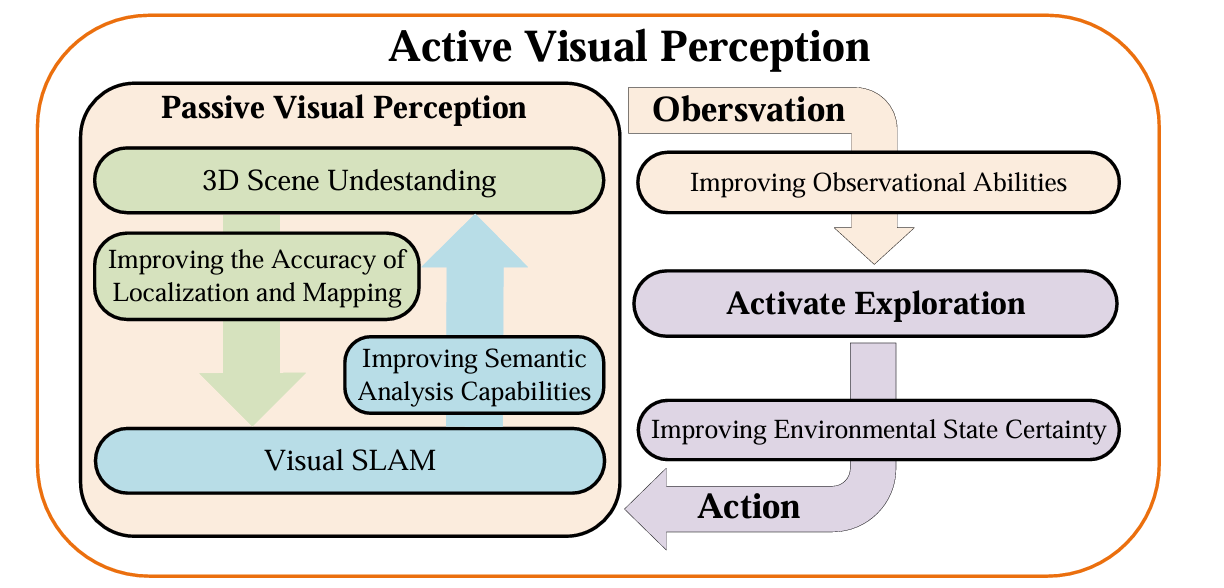
1)视觉SLAM:SLAM是一种技术,可以确定移动机器人在未知环境中的位置,同时竞争性地构建该环境的地图。基于距离的SLAM使用测距仪(如激光扫描仪、雷达和/或声纳)创建点云表示,但成本高昂,提供的环境信息有限。视觉SLAM(vSLAM)使用车载摄像头捕捉帧并构建环境表示。它因其低硬件成本、小规模场景中的高精度以及捕获丰富环境信息的能力而广受欢迎。经典的vSLAM技术可分为传统vSLAM和语义vSLAM。
2)3D场景理解:3D场景理解旨在区分目标的语义,识别它们的位置,并从3D场景数据中推断出几何属性,这在自动驾驶、机器人导航和人机交互等领域至关重要。场景可以使用激光雷达或RGB-D传感器等3D扫描工具记录为3D点云。与图像不同,点云是稀疏、无序和不规则的,这使得场景解释极具挑战性。
3)主动探索:之前介绍的3D场景理解方法赋予机器人以被动方式感知环境的能力。在这种情况下,感知系统的信息获取和决策不适应不断变化的场景。然而,被动感知是主动探索的重要基础。鉴于机器人能够移动并与周围环境频繁互动,它们也应该能够主动探索和感知周围的环境。它们之间的关系如图所示。当前解决主动感知的方法侧重于与环境交互或通过改变观察方向来获得更多的视觉信息。
2.2 3D Visual Grounding
与在平面图像范围内运行的传统2D视觉基础(VG)不同,3D VG结合了目标之间的深度、视角和空间关系,为代理与环境交互提供了更强大的框架。3D VG的任务涉及使用自然语言描述在3D环境中定位目标。如表五所示,3D视觉接地的最新方法大致可分为两类:两阶段方法和一阶段方法。这类方法主要集中在机械臂智能抓取的工作以及延伸下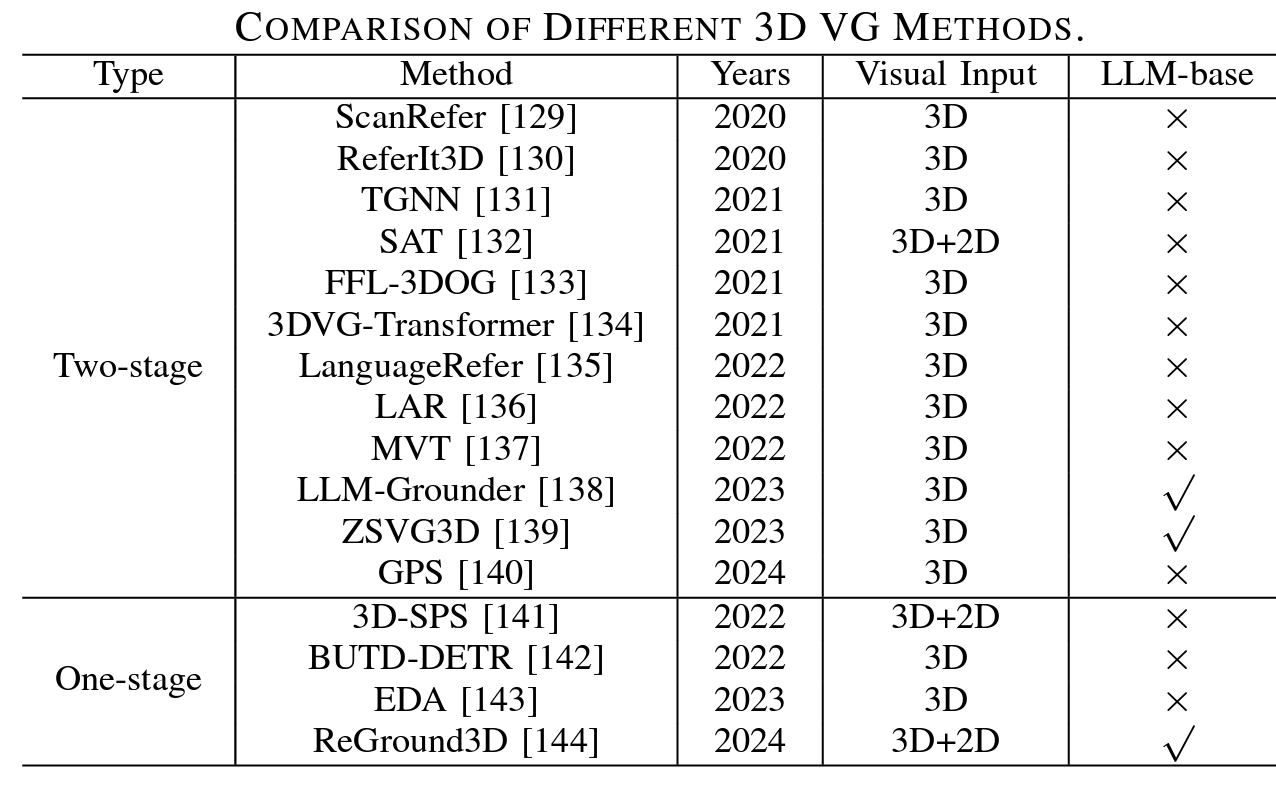
1)两阶段3D视觉接地方法:与相应的2D任务类似,3D接地的早期研究主要利用了两阶段检测然后匹配的管道。他们最初使用预训练的检测器或片段从3D场景中的众多目标建议中提取特征,然后将其与语言查询特征融合以匹配目标目标。两阶段研究的重点主要集中在第二阶段,例如探索目标建议特征和语言查询特征之间的相关性,以选择最匹配的目标。Refrait3D和TGNN不仅学习将提出的特征与文本嵌入相匹配,还通过图神经网络对目标之间的上下文关系进行编码。为了增强自由形式描述和不规则点云的3D视觉基础,FFL-3DOG使用了用于短语相关性的语言场景图、用于丰富视觉特征的多级3D提案关系图和用于编码全局上下文的描述引导3D视觉图。
2)一阶段3D视觉接地方法:在图(c)中,与两阶段3D VG方法相比,一阶段3D VGs方法集成了由语言查询引导的目标检测和特征提取,使定位与语言相关的目标变得更加容易。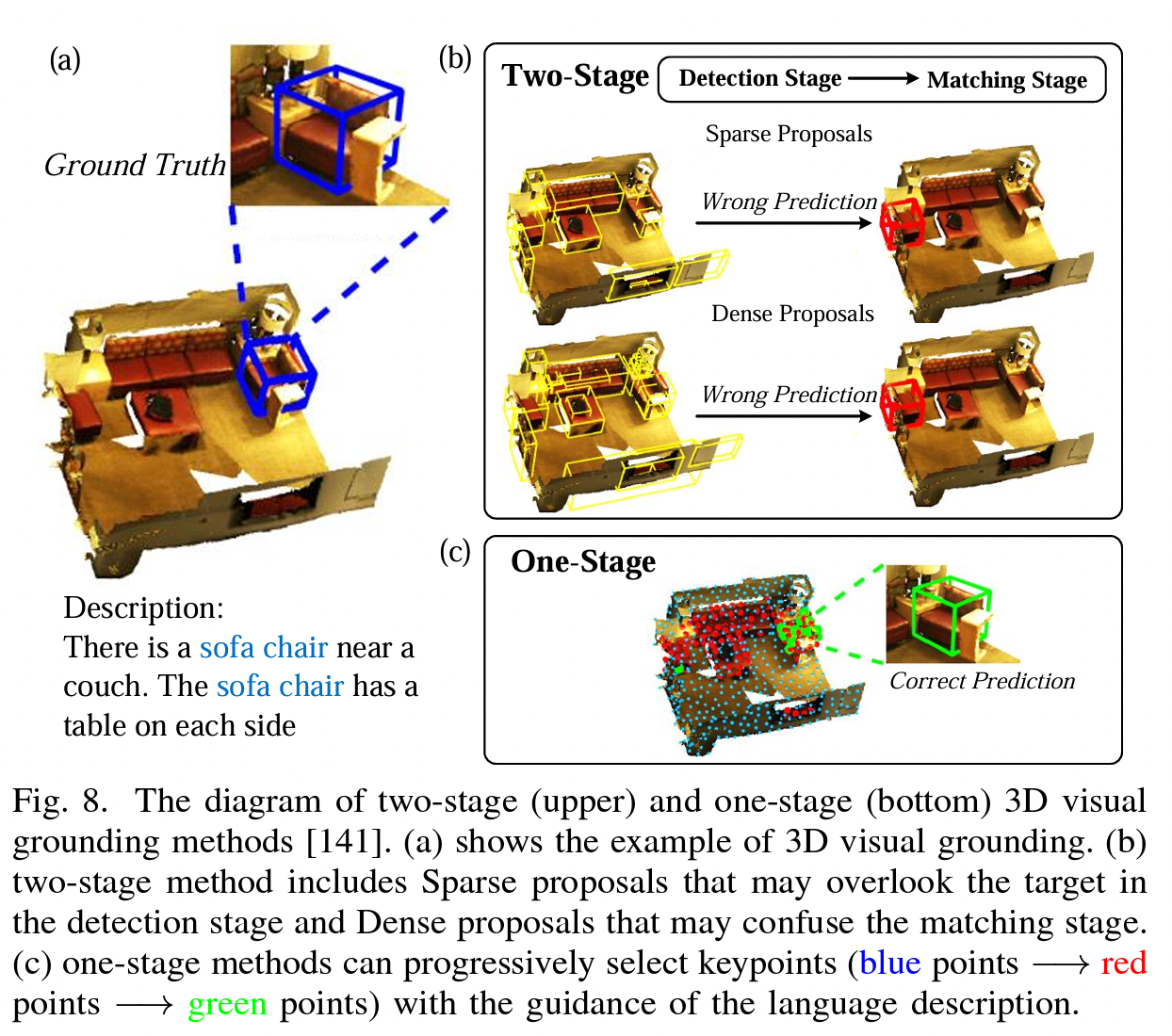
2.3 Visual Language Navigation
视觉语言导航(VLN)是具身智能的一个关键研究问题,旨在使代理能够按照语言指令在看不见的环境中导航。VLN要求机器人理解复杂多样的视觉观察,同时解释不同粒度的指令。VLN的输入通常由两部分组成:视觉信息和自然语言指令。视觉信息可以是过去轨迹的视频,也可以是一组历史当前观测图像。自然语言指令包括体现代理需要达到的目标或体现代理预期完成的任务。所体现的代理必须使用上述信息从候选列表中选择一个或一系列动作,以满足自然语言指令的要求。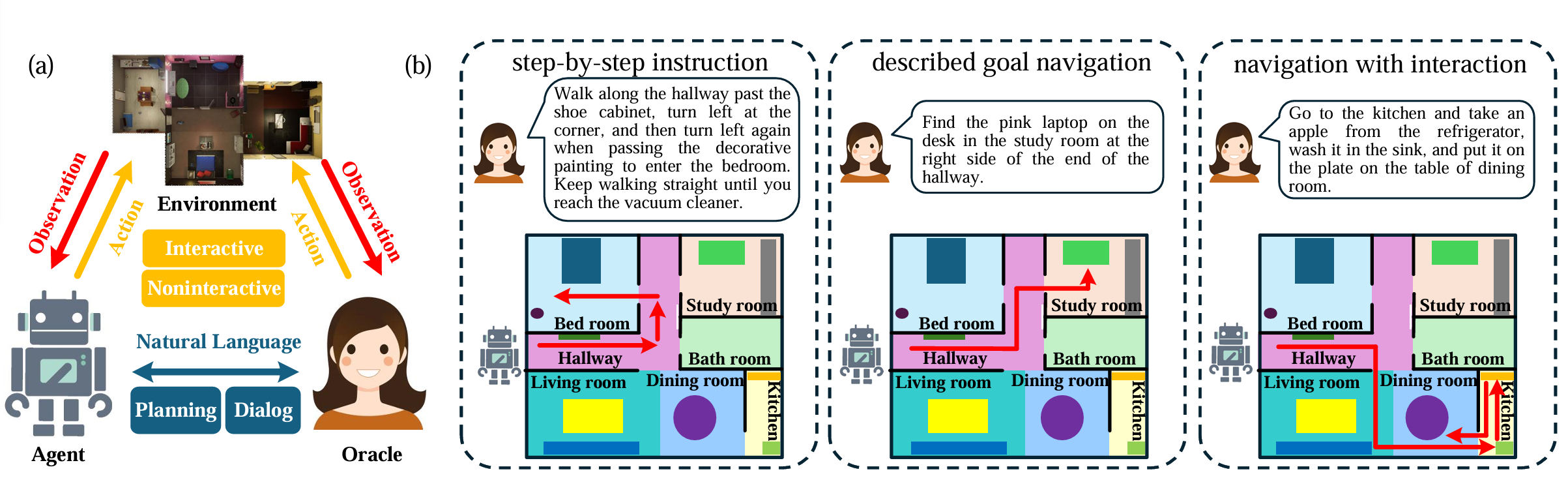
近年来,随着LLM的惊人性能,VLN取得了长足的进步,VLN的方向和重点受到了深刻的影响。VLN方法可以分为两个方向:基于记忆理解和基于未来预测。
数据集
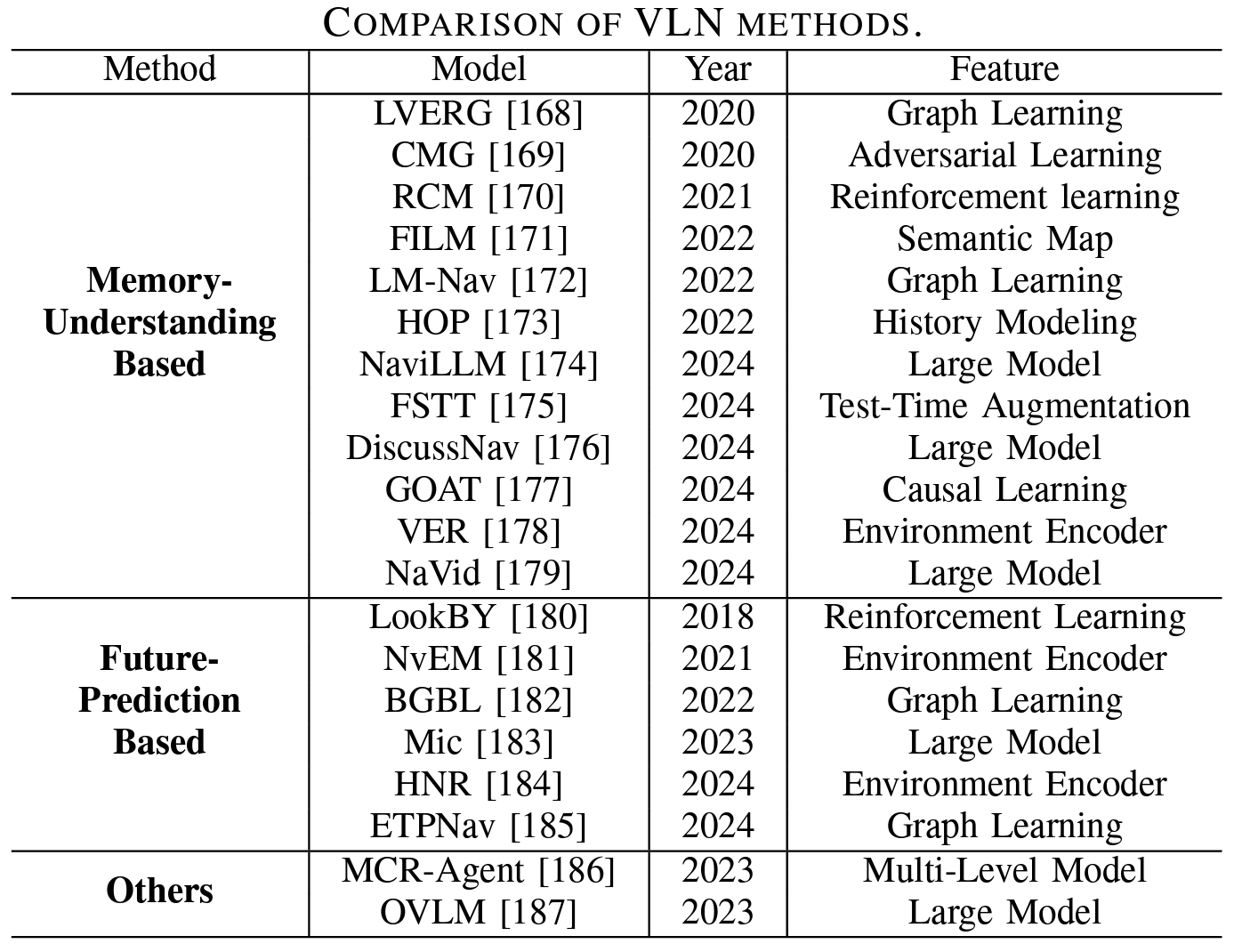
主要方法
2.4 Non-Visual Perception
触觉传感器为试剂提供有关物体属性的详细信息,如纹理、硬度和温度。它允许机器人完全完成手头的高精度任务,这对物理世界中的代理至关重要。触觉感知无疑增强了人机交互,并具有巨大的前景。
对于触觉感知任务,智能体需要从物理世界收集触觉信息,然后执行复杂的任务。在本节中,如图所示,我们介绍了现有类型的触觉传感器及其数据集,并讨论了触觉感知中的三个主要任务:估计、识别和操纵。这个也是在机械臂和灵巧手上主要关注的。
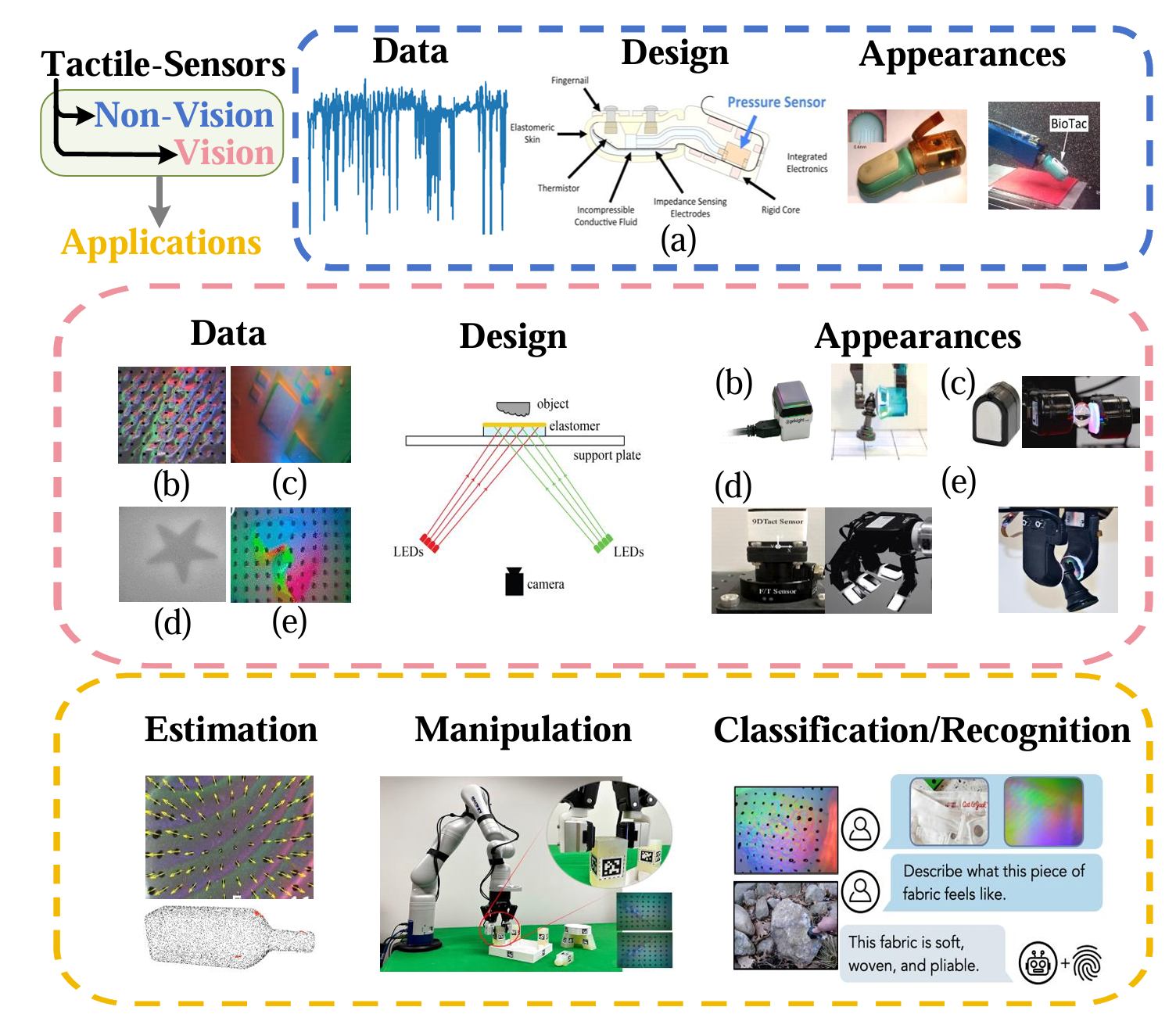
传感器设计:人类触觉的原理是,皮肤在被触摸时会改变形状,其丰富的神经细胞会发送电信号,这也是设计触觉传感器的基础。触觉传感器设计方法可分为三类:非视觉、视觉和多模态。非视觉触觉传感器主要使用电气和机械原理,主要记录基本的低维传感器输出,如力、压力、振动和温度。
数据集:非视觉传感器的数据集包含电极值、3D净力矢量和接触位置。因此,数据集中的对象通常是力样本和抓取样本。它的任务主要是估计力类型、力值和掌握细节。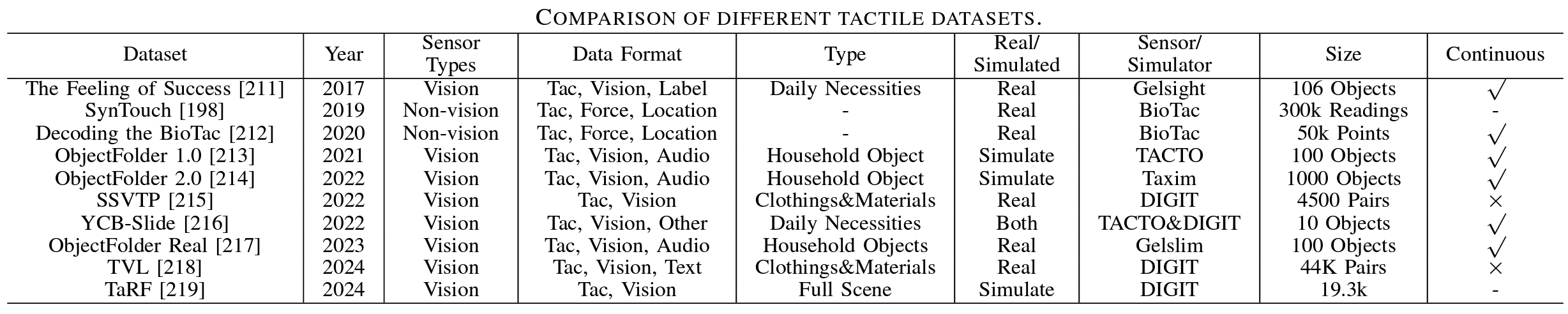
3. 具身交互
具身交互任务是指代理在物理或模拟空间中与人类和环境交互的场景。典型的具身交互任务是具身问答(EQA)和具身抓取。
3.1 Embodied Question Answering
对于EQA任务,代理需要从第一人称的角度探索环境,以收集回答给定问题所需的信息。具有自主探索和决策能力的代理不仅必须考虑采取哪些行动来探索环境,还必须确定何时停止探索以回答问题。现有的工作侧重于不同类型的问题,其中一些问题如图所示。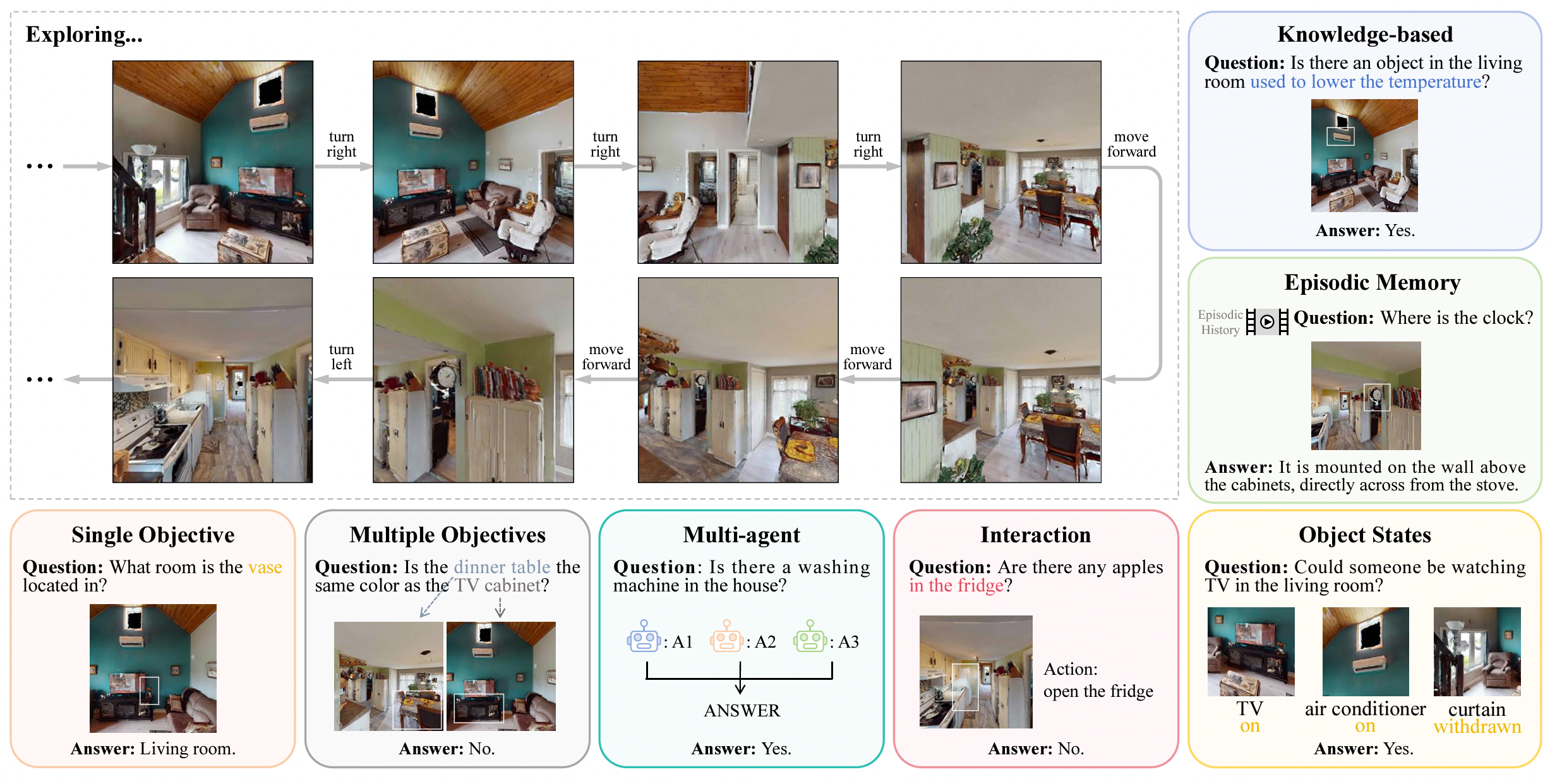
数据集如下:
3.2 Embodied Grasping
具身交互,除了与人类进行问答交互外,还可以包括根据人类指令执行操作,例如抓取和放置物体,从而完成机器人、人类和物体之间的交互。体现抓取需要全面的语义理解、场景感知、决策和稳健的控制规划。具身抓取方法将传统的机器人运动学抓取与大型模型(如LLM和视觉语言基础模型)相结合,使代理能够在多感官感知下执行抓取任务,包括视觉主动感知、语言理解和推理。图(b)展示了人机交互的概览,其中代理完成了具体的抓取任务。
3.3 具身agent
代理被定义为能够感知其环境并采取行动实现特定目标的自主具身。MLM的最新进展进一步将代理的应用扩展到实际场景。当这些基于MLM的代理体现在物理具身中时,它们可以有效地将其能力从虚拟空间转移到物理世界,从而成为体现代理。
为了使具身代理能够在信息丰富和复杂的现实世界中运行,开发了具身代理,以显示强大的多模态感知、交互和规划能力,如图13所示。为了完成一项任务,嵌入式代理通常涉及以下过程:1)将抽象和复杂的任务分解为特定的子任务,这被称为高级嵌入式任务规划。2)通过有效地利用体现感知和体现交互模型或利用基础模型的策略功能(称为低级体现行动计划)来逐步实现这些子任务。值得注意的是,任务规划涉及行动前的思考,因此通常在网络空间中被考虑。相比之下,行动计划必须考虑到与环境的有效交互,并将此信息反馈给任务规划者以调整任务计划。因此,对于具身代理来说,将他们的能力从网络空间推广到物理世界是至关重要的
3.4 Embodied Multimodal Foundation Model
具身代理需要视觉识别其环境,听觉理解指令,并包含其自身状态,以实现复杂的交互和操作。这需要一个集成多种传感器模态和自然语言处理能力的模型,通过合成各种数据类型来增强智能体的理解和决策。体现多模式基础模型正在出现。谷歌DeepMind八年前开始在机器人基础模型领域进行研究,不断探索更有效地扩展模型和数据的方法。他们的研究结果表明,利用基础模型和大型、多样化的数据集是最佳策略。他们基于机器人Transformer(RT)开发了一系列作品,为未来关于具身代理的研究提供了实质性的见解。
3.5 Embodied Task Planning
如前所述,对于“把苹果放在盘子里”的任务,任务规划器会将其分为“找到苹果,摘苹果”、“找到盘子”、“放下苹果”等子任务。因为如何查找(导航任务)或拾取/放下动作(抓取任务)不在任务规划的范围内。这些动作通常在模拟器中预先定义,或在现实世界中使用预先训练的策略模型执行,例如使用CLIPort来抓取任务。主要分为以下几个模块:
Planning utilizing the Emergent Capabilities of LLMs
Planning utilizing the visual information from embodied perception model
Planning utilizing the VLMs
3.6 Embodied Action Planning
很明显,行动规划必须解决现实世界的不确定性,因为任务规划提供的子任务的粒度不足以指导环境交互中的代理。通常,代理可以通过两种方式实现行动计划:1)使用预先训练的具身感知和具身干预模型作为工具,通过API逐步完成任务计划指定的子任务,2)利用VLA模型的固有能力来制定行动计划。此外,动作规划器的执行结果被反馈给任务规划器,以调整和改进任务规划。
Action utilizing APIs
Action utilizing VLA model
4. 主要具身实验室
…详情请参照古月居

「智能机器人开发者大赛」官方平台,致力于为开发者和参赛选手提供赛事技术指导、行业标准解读及团队实战案例解析;聚焦智能机器人开发全栈技术闭环,助力开发者攻克技术瓶颈,促进软硬件集成、场景应用及商业化落地的深度研讨。 加入智能机器人开发者社区iRobot Developer,与全球极客并肩突破技术边界,定义机器人开发的未来范式!
更多推荐


 24
24 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)